
Welcome to our p-value calculator! You will never again have to wonder how to find the p-value, as here you can determine the one-sided and two-sided p-values from test statistics, following all the most popular distributions: normal, t-Student, chi-squared, and Snedecor's F.
P-values appear all over science, yet many people find the concept a bit intimidating. Don't worry – in this article, we will explain not only what the p-value is but also how to interpret p-values correctly. Have you ever been curious about how to calculate the p-value by hand? We provide you with all the necessary formulae as well!
🙋 If you want to revise some basics from statistics, our normal distribution calculator is an excellent place to start.
📊 Your Real-World Statistics Resource Hub
Discover our full that includes expert articles and reports — all in one place!
Popular reads:
What is p-value?
Formally, the p-value is the probability that the test statistic will produce values at least as extreme as the value it produced for your sample. It is crucial to remember that this probability is calculated under the assumption that the null hypothesis H0 is true!
More intuitively, p-value answers the question:
Assuming that I live in a world where the null hypothesis holds, how probable is it that, for another sample, the test I'm performing will generate a value at least as extreme as the one I observed for the sample I already have?
It is the alternative hypothesis that determines what "extreme" actually means, so the p-value depends on the alternative hypothesis that you state: left-tailed, right-tailed, or two-tailed. In the formulas below, S stands for a test statistic, x for the value it produced for a given sample, and Pr(event | H0) is the probability of an event, calculated under the assumption that H0 is true:
-
Left-tailed test: p-value = Pr(S ≤ x | H0)
-
Right-tailed test: p-value = Pr(S ≥ x | H0)
-
Two-tailed test:
p-value = 2 × min{Pr(S ≤ x | H0), Pr(S ≥ x | H0)}
(By min{a,b}, we denote the smaller number out of a and b.)
If the distribution of the test statistic under H0 is symmetric about 0, then:
p-value = 2 × Pr(S ≥ |x| | H0)or, equivalently:
p-value = 2 × Pr(S ≤ -|x| | H0)
As a picture is worth a thousand words, let us illustrate these definitions. Here, we use the fact that the probability can be neatly depicted as the area under the density curve for a given distribution. We give two sets of pictures: one for a symmetric distribution and the other for a skewed (non-symmetric) distribution.
- Symmetric case: normal distribution:
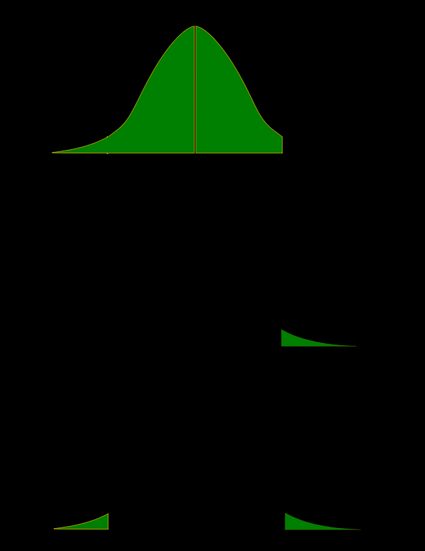
- Non-symmetric case: chi-squared distribution:
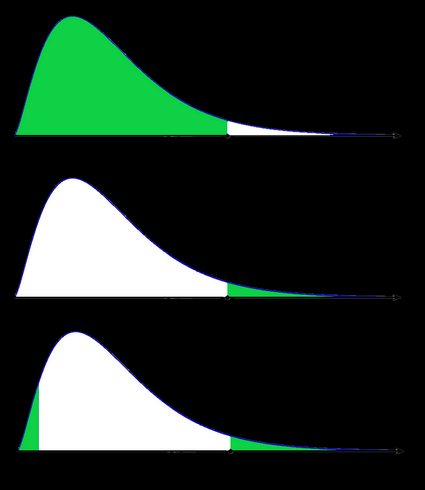
In the last picture (two-tailed p-value for skewed distribution), the area of the left-hand side is equal to the area of the right-hand side.
How do I calculate p-value from test statistic?
To determine the p-value, you need to know the distribution of your test statistic under the assumption that the null hypothesis is true. Then, with the help of the cumulative distribution function (cdf) of this distribution, we can express the probability of the test statistics being at least as extreme as its value x for the sample:
-
Left-tailed test:
p-value = cdf(x).
-
Right-tailed test:
p-value = 1 - cdf(x).
-
Two-tailed test:
p-value = 2 × min{cdf(x) , 1 - cdf(x)}.
If the distribution of the test statistic under H0 is symmetric about 0, then a two-sided p-value can be simplified to p-value = 2 × cdf(-|x|), or, equivalently, as p-value = 2 - 2 × cdf(|x|).
The probability distributions that are most widespread in hypothesis testing tend to have complicated cdf formulae, and finding the p-value by hand may not be possible. You'll likely need to resort to a computer or to a statistical table, where people have gathered approximate cdf values.
Well, you now know how to calculate the p-value, but… why do you need to calculate this number in the first place? In hypothesis testing, the p-value approach is an alternative to the critical value approach. Recall that the latter requires researchers to pre-set the significance level, α, which is the probability of rejecting the null hypothesis when it is true (so of type I error). Once you have your p-value, you just need to compare it with any given α to quickly decide whether or not to reject the null hypothesis at that significance level, α. For details, check the next section, where we explain how to interpret p-values.
Discover more about this in our article: P-value for the Null Hypothesis: When to Reject the Null Hypothesis.
How to interpret p-value
As we have mentioned above, the p-value is the answer to the following question:
Assuming that I live in a world where the null hypothesis holds, how probable is it that, for another sample, the test I'm performing will generate a value at least as extreme as the one I observed for the sample I already have?
What does that mean for you? Well, you've got two options:
- A high p-value means that your data is highly compatible with the null hypothesis; and
- A small p-value provides evidence against the null hypothesis, as it means that your result would be very improbable if the null hypothesis were true.
However, it may happen that the null hypothesis is true, but your sample is highly unusual! For example, imagine we studied the effect of a new drug and got a p-value of 0.03. This means that in 3% of similar studies, random chance alone would still be able to produce the value of the test statistic that we obtained, or a value even more extreme, even if the drug had no effect at all!
The question "what is p-value" can also be answered as follows: p-value is the smallest level of significance at which the null hypothesis would be rejected. So, if you now want to make a decision on the null hypothesis at some significance level α, just compare your p-value with α:
- If p-value ≤ α, then you reject the null hypothesis and accept the alternative hypothesis; and
- If p-value ≥ α, then you don't have enough evidence to reject the null hypothesis.
Obviously, the fate of the null hypothesis depends on α. For instance, if the p-value was 0.03, we would reject the null hypothesis at a significance level of 0.05, but not at a level of 0.01. That's why the significance level should be stated in advance and not adapted conveniently after the p-value has been established! A significance level of 0.05 is the most common value, but there's nothing magical about it. It's always best to report the p-value, and allow the reader to make their own conclusions. To learn even more about it, you can read our article: A p-value Less Than 0.05 — What Does it Mean?.
Also, bear in mind that subject area expertise (and common reason) is crucial. Otherwise, mindlessly applying statistical principles, you can easily arrive at
How to calculate the p-value by hand?
If you want to determine p-value by hand, follow the steps below:
- Define null and alternative hypotheses;
- Calculate the test statistic;
- Determine the distribution of test statistics;
- Find the p-value using a table or this p-value calculator; and
- Compare the p-value to the significance level.
How to use the p-value calculator to find p-value from test statistic
As our p-value calculator is here at your service, you no longer need to wonder how to find p-value from all those complicated test statistics! Here are the steps you need to follow:
-
Pick the alternative hypothesis: two-tailed, right-tailed, or left-tailed.
-
Tell us the distribution of your test statistic under the null hypothesis: is it N(0,1), t-Student, chi-squared, or Snedecor's F? If you are unsure, check the sections below, as they are devoted to these distributions.
-
If needed, specify the degrees of freedom of the test statistic's distribution.
-
Enter the value of test statistic computed for your data sample.
-
By default, the calculator uses the significance level of 0.05.
-
Our calculator determines the p-value from the test statistic and provides the decision to be made about the null hypothesis.
How do I find p-value from z-score?
In terms of the cumulative distribution function (cdf) of the standard normal distribution, which is traditionally denoted by Φ, the p-value is given by the following formulae:
-
Left-tailed z-test:
p-value = Φ(Zscore)
-
Right-tailed z-test:
p-value = 1 - Φ(Zscore)
-
Two-tailed z-test:
p-value = 2 × Φ(−|Zscore|)
or
p-value = 2 - 2 × Φ(|Zscore|)
🙋 To learn more about Z-tests, head to Omni's Z-test calculator.
We use the Z-score if the test statistic approximately follows the standard normal distribution N(0,1). Thanks to the central limit theorem, you can count on the approximation if you have a large sample (say at least 50 data points) and treat your distribution as normal.
A Z-test most often refers to testing the population mean, or the difference between two population means, in particular between two proportions. You can also find Z-tests in maximum likelihood estimations.

P-value from z-score: an example
We can explore the process of finding the p-value from the Z-score with an example. Let's say that a consumer rights company wants to test the null hypothesis using nuts packs. Each regular nuts pack has exactly 78 nuts, and the company can test this affirmative against the null hypothesis, which states that the nuts pack does not have 78 nuts.
By considering that in a sample of 100 packets, the mean amount of nuts is 76 with a population standard deviation of 13.5, and the population mean is 80. Does a two-tailed test provide enough evidence to reject the null hypothesis?
To find the answer, let us compute the Z-score by setting: , , , and . Now, we can substitute these parameters in the formula for the Z-score:
From a z-score table, we can verify that Φ(2.96) = 0.0015, therefore, p-value = 2 × 0.0015 = 0.003.
Thus, since 0.003<0.05, the null hypothesis is statistically significant.
How do I find p-value from t?
The p-value from the t-score is given by the following formulae, in which cdft,d stands for the cumulative distribution function of the t-Student distribution with d degrees of freedom:
-
Left-tailed t-test:
p-value = cdft,d(tscore)
-
Right-tailed t-test:
p-value = 1 - cdft,d(tscore)
-
Two-tailed t-test:
p-value = 2 × cdft,d(−|tscore|)
or
p-value = 2 - 2 × cdft,d(|tscore|)
Use the t-score option if your test statistic follows the t-Student distribution. This distribution has a shape similar to N(0,1) (bell-shaped and symmetric) but has heavier tails – the exact shape depends on the parameter called the degrees of freedom. If the number of degrees of freedom is large (>30), which generically happens for large samples, the t-Student distribution is practically indistinguishable from the normal distribution N(0,1).

The most common t-tests are those for population means with an unknown population standard deviation, or for the difference between means of two populations, with either equal or unequal yet unknown population standard deviations. There's also a t-test for paired (dependent) samples.
🙋 To get more insights into t-statistics, we recommend using our t-test calculator.
p-value from chi-square score (χ² score)
Use the χ²-score option when performing a test in which the test statistic follows the χ²-distribution.
This distribution arises if, for example, you take the sum of squared variables, each following the normal distribution N(0,1). Remember to check the number of degrees of freedom of the χ²-distribution of your test statistic!

How to find the p-value from chi-square-score? You can do it with the help of the following formulae, in which cdfχ²,d denotes the cumulative distribution function of the χ²-distribution with d degrees of freedom:
-
Left-tailed χ²-test:
p-value = cdfχ²,d(χ²score)
-
Right-tailed χ²-test:
p-value = 1 - cdfχ²,d(χ²score)
Remember that χ²-tests for goodness-of-fit and independence are right-tailed tests! (see below)
-
Two-tailed χ²-test:
p-value = 2 × min{cdfχ²,d(χ²score), 1 - cdfχ²,d(χ²score)}
(By min{a,b}, we denote the smaller of the numbers a and b.)
The most popular tests which lead to a χ²-score are the following:
-
Testing whether the variance of normally distributed data has some pre-determined value. In this case, the test statistic has the χ²-distribution with n - 1 degrees of freedom, where n is the sample size. This can be a one-tailed or two-tailed test.
-
Goodness-of-fit test checks whether the empirical (sample) distribution agrees with some expected probability distribution. In this case, the test statistic follows the χ²-distribution with k - 1 degrees of freedom, where k is the number of classes into which the sample is divided. This is a right-tailed test.
-
Independence test is used to determine if there is a statistically significant relationship between two variables. In this case, its test statistic is based on the contingency table and follows the χ²-distribution with (r - 1)(c - 1) degrees of freedom, where r is the number of rows, and c is the number of columns in this contingency table. This also is a right-tailed test.
p-value from F-score
Finally, the F-score option should be used when you perform a test in which the test statistic follows the F-distribution, also known as the Fisher–Snedecor distribution. The exact shape of an F-distribution depends on two degrees of freedom.

To see where those degrees of freedom come from, consider the independent random variables X and Y, which both follow the χ²-distributions with d1 and d2 degrees of freedom, respectively. In that case, the ratio (X/d1)/(Y/d2) follows the F-distribution, with (d1, d2)-degrees of freedom. For this reason, the two parameters d1 and d2 are also called the numerator and denominator degrees of freedom.
The p-value from F-score is given by the following formulae, where we let cdfF,d1,d2 denote the cumulative distribution function of the F-distribution, with (d1, d2)-degrees of freedom:
-
Left-tailed F-test:
p-value = cdfF,d1,d2(Fscore)
-
Right-tailed F-test:
p-value = 1 - cdfF,d1,d2(Fscore)
-
Two-tailed F-test:
p-value = 2 × min{cdfF,d1,d2(Fscore), 1 - cdfF,d1,d2(Fscore)}
(By min{a,b}, we denote the smaller of the numbers a and b.)
Below we list the most important tests that produce F-scores. All of them are right-tailed tests.
-
A test for the equality of variances in two normally distributed populations. Its test statistic follows the F-distribution with (n - 1, m - 1)-degrees of freedom, where n and m are the respective sample sizes.
-
ANOVA is used to test the equality of means in three or more groups that come from normally distributed populations with equal variances. We arrive at the F-distribution with (k - 1, n - k)-degrees of freedom, where k is the number of groups, and n is the total sample size (in all groups together).
-
A test for overall significance of regression analysis. The test statistic has an F-distribution with (k - 1, n - k)-degrees of freedom, where n is the sample size, and k is the number of variables (including the intercept).
With the presence of the linear relationship having been established in your data sample with the above test, you can calculate the coefficient of determination, R2, which indicates the strength of this relationship. You can do it by hand or use our coefficient of determination calculator.
-
A test to compare two nested regression models. The test statistic follows the F-distribution with (k2 - k1, n - k2)-degrees of freedom, where k1 and k2 are the numbers of variables in the smaller and bigger models, respectively, and n is the sample size.
You may notice that the F-test of an overall significance is a particular form of the F-test for comparing two nested models: it tests whether our model does significantly better than the model with no predictors (i.e., the intercept-only model).
FAQs
Can p-value be negative?
No, the p-value cannot be negative. This is because probabilities cannot be negative, and the p-value is the probability of the test statistic satisfying certain conditions.
What does a high p-value mean?
A high p-value means that under the null hypothesis, there's a high probability that for another sample, the test statistic will generate a value at least as extreme as the one observed in the sample you already have. A high p-value doesn't allow you to reject the null hypothesis.
What does a low p-value mean?
A low p-value means that under the null hypothesis, there's little probability that for another sample, the test statistic will generate a value at least as extreme as the one observed for the sample you already have. A low p-value is evidence in favor of the alternative hypothesis – it allows you to reject the null hypothesis.