This Z-test calculator is a tool that helps you perform a one-sample Z-test on the population's mean. Two forms of this test - a two-tailed Z-test and a one-tailed Z-tests - exist, and can be used depending on your needs. You can also choose whether the calculator should determine the p-value from Z-test or you'd rather use the critical value approach!
Read on to learn more about Z-test in statistics, and, in particular, when to use Z-tests, what is the Z-test formula, and whether to use Z-test vs. t-test. As a bonus, we give some step-by-step examples of how to perform Z-tests!
A common application of the two-proportion z-test is A/B testing. You can learn more with our dedicated AB test calculator.
As a next step, you may check our t-statistic calculator, where you can discover another essential test statistic. If you are also interested in F-test, check our F-statistic calculator.
What is a Z-test?
A one sample Z-test is one of the most popular location tests. The null hypothesis is that the population mean value is equal to a given number, :
We perform a two-tailed Z-test if we want to test whether the population mean is not :
and a one-tailed Z-test if we want to test whether the population mean is less/greater than :
Let us now discuss the assumptions of a one-sample Z-test.
When do I use Z-tests?
You may use a Z-test if your sample consists of independent data points and:
-
the data is normally distributed, and you know the population variance;
or
-
the sample is large, and data follows a distribution which has a finite mean and variance. You don't need to know the population variance.
The reason these two possibilities exist is that we want the test statistics that follow the standard normal distribution . In the former case, it is an exact standard normal distribution, while in the latter, it is approximately so, thanks to the central limit theorem.
The question remains, "When is my sample considered large?" Well, there's no universal criterion. In general, the more data points you have, the better the approximation works. Statistics textbooks recommend having no fewer than 50 data points, while 30 is considered the bare minimum.
Z-test formula
Let be an independent sample following the normal distribution , i.e., with a mean equal to , and variance equal to .
We pose the null hypothesis, .
We define the test statistic, Z, as:
where:
-
is the sample mean, i.e., ;
-
is the mean postulated in ;
-
is sample size; and
-
is the population standard deviation.
In what follows, the uppercase stands for the test statistic (treated as a random variable), while the lowercase will denote an actual value of , computed for a given sample drawn from N(μ,σ²).
If holds, then the sum follows the normal distribution, with mean and variance . As is the standardization (z-score) of , we can conclude that the test statistic follows the standard normal distribution , provided that is true. By the way, we have the z-score calculator if you want to focus on this value alone, and an article on the Z-score and p-value to better understand both concepts.
If our data does not follow a normal distribution, or if the population standard deviation is unknown (and thus in the formula for we substitute the population standard deviation with sample standard deviation), then the test statistics is not necessarily normal. However, if the sample is sufficiently large, then the central limit theorem guarantees that is approximately .
In the sections below, we will explain to you how to use the value of the test statistic, , to make a decision, whether or not you should reject the null hypothesis. Two approaches can be used in order to arrive at that decision: the p-value approach, and critical value approach - and we cover both of them! Which one should you use? In the past, the critical value approach was more popular because it was difficult to calculate p-value from Z-test. However, with help of modern computers, we can do it fairly easily, and with decent precision. In general, you are strongly advised to report the p-value of your tests!
p-value from Z-test
Formally, the p-value is the smallest level of significance at which the null hypothesis could be rejected. More intuitively, p-value answers the questions:
provided that I live in a world where the null hypothesis holds, how probable is it that the value of the test statistic will be at least as extreme as the -value I've got for my sample? Hence, a small p-value means that your result is very improbable under the null hypothesis, and so there is strong evidence against the null hypothesis - the smaller the p-value, the stronger the evidence.
To find the p-value, you have to calculate the probability that the test statistic, , is at least as extreme as the value we've actually observed, , provided that the null hypothesis is true. (The probability of an event calculated under the assumption that is true will be denoted as .) It is the alternative hypothesis which determines what more extreme means:
- Two-tailed Z-test: extreme values are those whose absolute value exceeds , so those smaller than or greater than . Therefore, we have:
The symmetry of the normal distribution gives:
- Left-tailed Z-test: extreme values are those smaller than , so
- Right-tailed Z-test: extreme values are those greater than , so
To compute these probabilities, we can use the cumulative distribution function, (cdf) of , which for a real number, , is defined as:
Also, p-values can be nicely depicted as the area under the probability density function (pdf) of , due to:
Two-tailed Z-test and one-tailed Z-test
With all the knowledge you've got from the previous section, you're ready to learn about Z-tests.
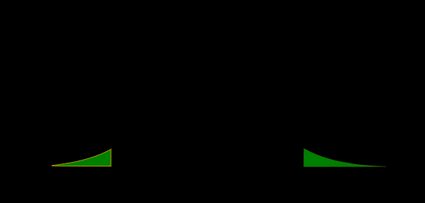
- Two-tailed Z-test:
From the fact that , we deduce that
The p-value is the area under the probability distribution function (pdf) both to the left of , and to the right of :
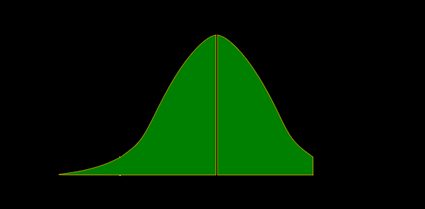
- Left-tailed Z-test:
The p-value is the area under the pdf to the left of our :
- Right-tailed Z-test:
The p-value is the area under the pdf to the right of :

The decision as to whether or not you should reject the null hypothesis can be now made at any significance level, , you desire!
-
if the p-value is less than, or equal to, , the null hypothesis is rejected at this significance level; and
-
if the p-value is greater than , then there is not enough evidence to reject the null hypothesis at this significance level.
Z-test critical values & critical regions
The critical value approach involves comparing the value of the test statistic obtained for our sample, , to the so-called critical values. These values constitute the boundaries of regions where the test statistic is highly improbable to lie. Those regions are often referred to as the critical regions, or rejection regions. The decision of whether or not you should reject the null hypothesis is then based on whether or not our belongs to the critical region.
The critical regions depend on a significance level, , of the test, and on the alternative hypothesis. The choice of is arbitrary; in practice, the values of 0.1, 0.05, or 0.01 are most commonly used as .
Once we agree on the value of , we can easily determine the critical regions of the Z-test:
- Two-tailed Z-test:
- Left-tailed Z-test:
- Right-tailed Z-test:
To decide the fate of , check whether or not your falls in the critical region:
-
If yes, then reject and accept ; and
-
If no, then there is not enough evidence to reject .
As you see, the formulae for the critical values of Z-tests involve the inverse, , of the cumulative distribution function (cdf) of .
How to use the one-sample Z-test calculator?
Our calculator reduces all the complicated steps:
-
Choose the alternative hypothesis: two-tailed or left/right-tailed.
-
In our Z-test calculator, you can decide whether to use the p-value or critical regions approach. In the latter case, set the significance level, .
-
Enter the value of the test statistic, . If you only have raw score, then you can enter some data that will allow us to calculate your for you:
- sample mean ;
- tested mean ;
- sample size ; and
- population standard deviation (or sample standard deviation if your sample is large).
-
Results appear immediately below the calculator.
If you want to find based on p-value, please remember that in the case of two-tailed tests there are two possible values of : one positive and one negative, and they are opposite numbers. This Z-test calculator returns the positive value in such a case. In order to find the other possible value of for a given p-value, just take the number opposite to the value of displayed by the calculator.
Z-test examples
To make sure that you've fully understood the essence of Z-test, let's go through some examples:
- A bottle filling machine follows a normal distribution. Its standard deviation, as declared by the manufacturer, is equal to 30 ml. A juice seller claims that the volume poured in each bottle is, on average, one liter, i.e., 1000 ml, but we suspect that in fact the average volume is smaller than that...
Formally, the hypotheses that we set are the following:
We went to a shop and bought a sample of 9 bottles. After carefully measuring the volume of juice in each bottle, we've obtained the following sample (in milliliters):
.
-
Sample size: ;
-
Sample mean: ;
-
Population standard deviation: ;
-
So
-
And, therefore, .
As , we conclude that our suspicions aren't groundless; at the most common significance level, 0.05, we would reject the producer's claim, , and accept the alternative hypothesis, .
-
We tossed a coin 50 times. We got 20 tails and 30 heads. Is there sufficient evidence to claim that the coin is biased?
Clearly, our data follows Bernoulli distribution, with some success probability and variance . However, the sample is large, so we can safely perform a Z-test. We adopt the convention that getting tails is a success.
Let us state the null and alternative hypotheses:
-
(the coin is fair - the probability of tails is )
-
(the coin is biased - the probability of tails differs from )
-
In our sample we have 20 successes (denoted by ones) and 30 failures (denoted by zeros), so:
-
Sample size ;
-
Sample mean ;
-
Population standard deviation is given by (because is the proportion hypothesized in ). Hence, ;
-
So
- And, therefore
Since we don't have enough evidence to reject the claim that the coin is fair, even at such a large significance level as . In that case, you may safely toss it to your Witcher or use the coin flip probability calculator to find your chances of getting, e.g., 10 heads in a row (which are extremely low!).
FAQs
What is the difference between Z-test vs t-test?
We use a t-test for testing the population mean of a normally distributed dataset which had an unknown population standard deviation. We get this by replacing the population standard deviation in the Z-test statistic formula by the sample standard deviation, which means that this new test statistic follows (provided that H₀ holds) the t-Student distribution with n-1 degrees of freedom instead of N(0,1).
When should I use t-test over the Z-test?
For large samples, the t-Student distribution with n degrees of freedom approaches the N(0,1). Hence, as long as there are a sufficient number of data points (at least 30), it does not really matter whether you use the Z-test or the t-test, since the results will be almost identical. However, for small samples with unknown variance, remember to use the t-test instead of Z-test.
How do I calculate the Z test statistic?
To calculate the Z test statistic:
- Compute the arithmetic mean of your sample.
- From this mean subtract the mean postulated in null hypothesis.
- Multiply by the square root of size sample.
- Divide by the population standard deviation.
- That's it, you've just computed the Z test statistic!