Table of contents
The ORCA Benchmark Evaluates How Well AIs Deal with Everyday Math
Report Highlights
- ORCA Benchmark reveals you have a 40% chance of getting a wrong answer when you ask AI for everyday math.
- Why AI chatbots give detailed, confident explanations for the wrong mathematical answers.
- Why the biggest AI models are failing at basic, everyday math.
- How a simple rounding error reveals the core limitation of large language models.
- Why AI is an unreliable calculator for your finances and your health.
That's the truth we uncovered after testing today's five leading AIs on 500 real-world problems.
From calculating a tip to projecting a business ROI, we're trusting AI with our most basic calculations. Our data reveals that trust could be dangerously misplaced.
The ORCA (Omni Research on Calculation in AI) Benchmark, a comprehensive test spanning finance, health, and physics, reveals that no AI model scored above 63%. The leader, Gemini, still gets nearly 4 out of 10 problems wrong. The most common culprits? Not complex logic, but simple rounding errors and calculation mistakes.
🔎 AIs aren't failing advanced calculus; they're failing the math that runs our daily lives.
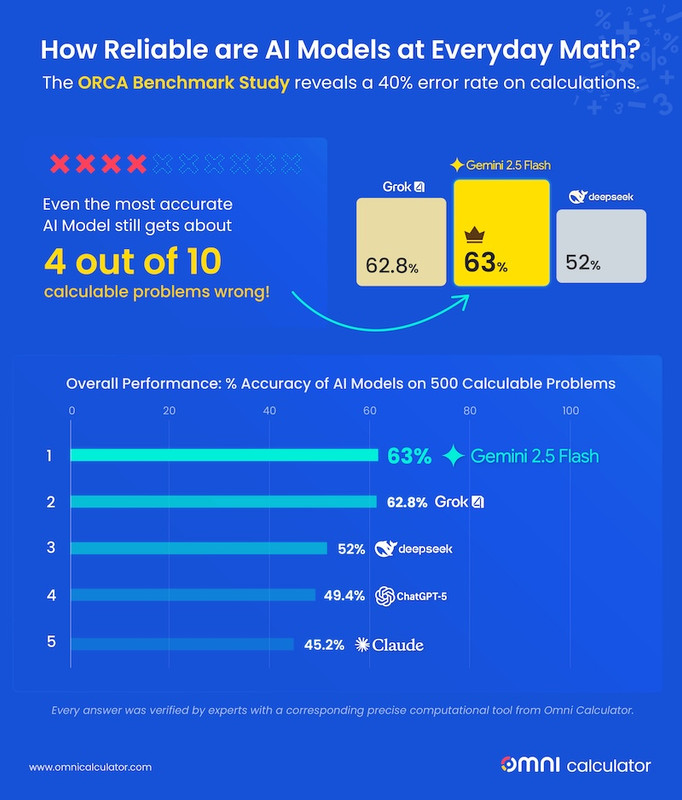
After putting the five leading AI models through this comprehensive test, the results are in: they're just not that good at everyday math yet. Despite their advanced technology, they often fail at the simple task of getting the numbers right.
If you ask any of these AI chatbots 10 calculation questions, you should expect about 4 of the answers to be wrong.
❓ Ask yourself: would you want advice on your mortgage from a financial expert who is wrong half of the time?
Overall Performance
-
Gemini and Grok Excel in Finance
The results revealed two winners for your wallet: Gemini and Grok. While other models showed general math skills, these two achieved accuracy rates above 75%, demonstrating an edge in the domain of Finance & Economics.In other words, if you're asking a question about loans, investments, or budgeting, Gemini and Grok are the models most likely to get it right.
-
Top and Bottom Performing Domains
The most consistently high-scoring domains were Math & Conversions, where most models performed above 65%. In stark contrast, Physics, Health & Sports, and Biology & Chemistry were the most challenging, with most models failing to achieve 50% accuracy.The challenge lies in "translating" a real-world situation into the right formula — and that's where the most significant errors happen. Straightforward, “clear” math problems are much easier for AIs to solve correctly.
Performance Across Different Domains
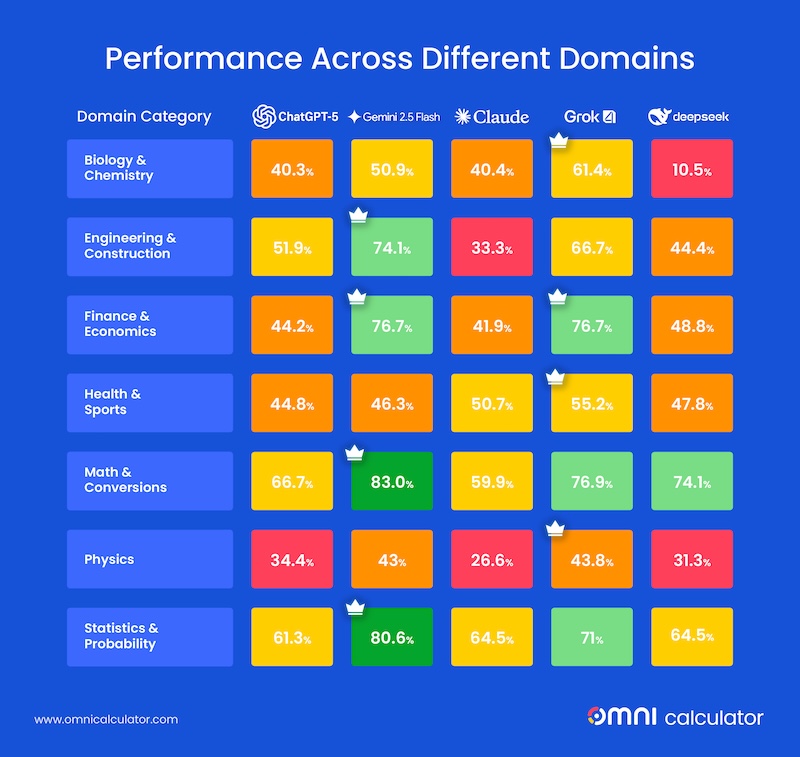
Model-by-Model Breakdown
- Gemini 2.5 Flash and Grok-4 were the top-tier performers, leading in most categories.
- Gemini also claimed a decisive victory in Statistics & Probability and in Math & Conversion, achieving an accuracy of 80.6% and 83%, respectively.
- DeepSeek V3.2 showed the most volatile performance. While it was strong in areas like Math & Conversion, its accuracy plummeted in Biology & Chemistry to just 10.5% and Physics at 31.3%, making it an unreliable choice for those sciences.
- Claude Sonnet 4.5 had the lowest scores in general, not even scoring above 65% or above in any domain category.
- ChatGPT-5 delivered moderate but more consistent results across the board.
Consistency and Volatility
The results also highlight how consistently the models performed within each domain:
- High-Consistency Domains: In Math & Conversions, all models performed at a similar level, 60% or above.
- High-Volatility Domains: In Biology & Chemistry and Physics, the gap between the best and worst models was enormous. For example, in Biology & Chemistry, Grok-4's accuracy at 61.4% was roughly 5.85 times higher than that of DeepSeek V3.2 at 10.5%.
The ORCA Benchmark study not only focuses on ranking the AI’s math capabilities, but also analyzes the types of errors they make. Thanks to this analysis, we gain deeper insight into not only when AIs get math wrong, but also why and how.
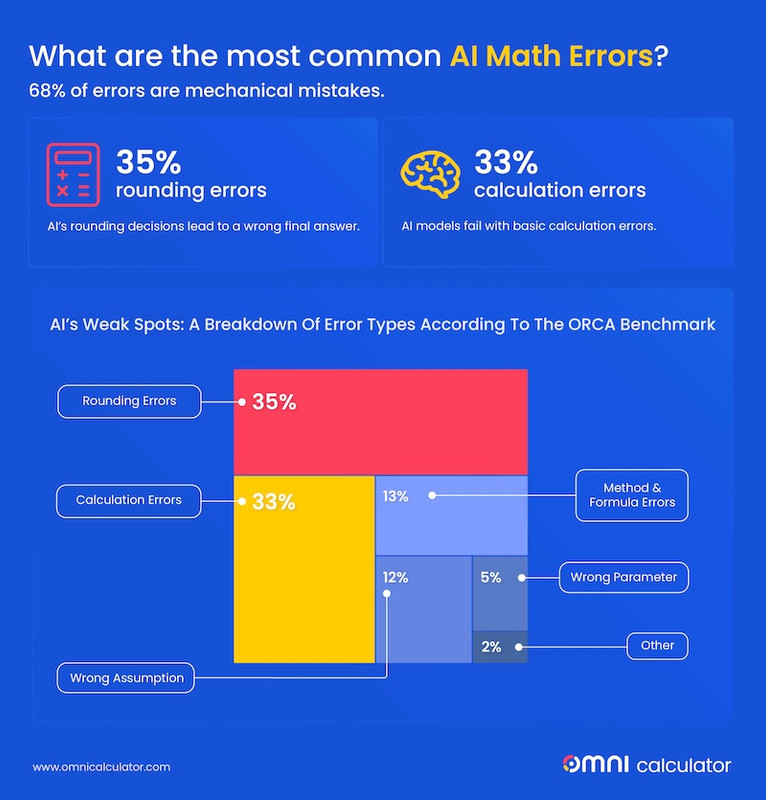
A Look at 4 AI Error Types and Sample Prompts
-
The "Sloppy Math" Errors (68% of all mistakes)
This is the most common type of failure, where the AI understands the question and knows the formula but trips over the computation itself.-
Precision & Rounding Issues (35%): The AI gets close, but small rounding decisions lead to an incorrect final answer.
- Example: When calculating a runner's VO2 max, Grok-4 produced 47.89 instead of 47.86. The difference seems tiny, but it resulted from truncating numbers mid-calculation — a fatal flaw in precise math.
- Prompt: What’s my VO2 max if I run 10.564 km in 45:28 minutes?
- VO2 max runners calculator result: 47.86 mL/kg/min
- Grok 4: 47.89 mL/kg/min
- Example: When calculating a runner's VO2 max, Grok-4 produced 47.89 instead of 47.86. The difference seems tiny, but it resulted from truncating numbers mid-calculation — a fatal flaw in precise math.
-
Calculation Errors (33%): Simple arithmetic failures.
- Example: Gemini miscalculated an improper fraction conversion, incorrectly calculating the remainder as 12,334,890 instead of 12,344,890 due to a simple arithmetic error in subtraction.
- Prompt: Convert to mixed number 987654321/12345689.
- Improper fraction to mixed number calculator result: 79 + 12344890/12345689 = 79 + 726170/726217
- Example: ChatGPT-5 miscomputed a lottery probability calculation, incorrectly calculating the odds as 1 in 401,397 instead of 1 in 520,521 due to a massive error in combinatorial math.
- Prompt: For a lottery where 6 balls are drawn from a pool of 76, what are my chances of matching 5 of them?
- Lottery calculator result: 1 in 520521
- ChatGPT-5: 1 in 401397
- Example: Gemini miscalculated an improper fraction conversion, incorrectly calculating the remainder as 12,334,890 instead of 12,344,890 due to a simple arithmetic error in subtraction.
-
-
The "Faulty Logic" Errors (26% of all mistakes)
These errors are concerning, as they indicate that the AI is struggling to grasp the core logic of a problem.- Method or Formula Errors (14%): Using a completely wrong mathematical approach.
- Example: Asked for the area of a hexagram, DeepSeek used a formula for a simple hexagon, yielding 21.65 cm² instead of the correct 129.9 cm².
- Prompt: What is the area of a hexagram with side length 5 cm?
- Star shape calculator result: 129.9 cm^2
- DeepSeek V2.3: 21.65 cm^2
- Example: Asked for the area of a hexagram, DeepSeek used a formula for a simple hexagon, yielding 21.65 cm² instead of the correct 129.9 cm².
- Wrong Assumptions (12%): The AI inserts its own flawed logic.
- Example: To predict a puppy's adult weight, DeepSeek incorrectly assumed a 3 kg puppy was 25% of its final size, guessing 26.32 lbs. The correct method, using a growth formula, gives 57.32 lbs.
- Prompt: What will the adult weight be in lbs of a 3 kg 6-week-old puppy?
- Dog size calculator result: 57.32 lb (51.59-63.05 lb)
- DeepSeek V2.3: 26.32 lb
- Example: To predict a puppy's adult weight, DeepSeek incorrectly assumed a 3 kg puppy was 25% of its final size, guessing 26.32 lbs. The correct method, using a growth formula, gives 57.32 lbs.
- Method or Formula Errors (14%): Using a completely wrong mathematical approach.
-
The "Misreading the Instructions" Errors (5% of all mistakes)
These errors highlight a failure to parse the details of a question correctly.- Wrong Parameter Errors: Misusing the given numbers.
- Example: In an LED circuit problem, Claude mistakenly applied a 5 mA current to each of the 7 LEDs, instead of using it as the total for the circuit. This led to a power calculation of 294 mW — seven times higher than the correct answer of 42 mW.
- Prompt: Consider that you have 7 blue LEDs (3.6V) connected in parallel, together with a resistor, subject to a voltage of 12 V and a current of 5 mA. What is the value of the power dissipation in the resistor (in mW)?
- LED resistor calculator result: 42 mW
- Claude Sonnet 4.5 result: 294 mW
- Example: In an LED circuit problem, Claude mistakenly applied a 5 mA current to each of the 7 LEDs, instead of using it as the total for the circuit. This led to a power calculation of 294 mW — seven times higher than the correct answer of 42 mW.
- Incomplete Answers:
- Example: When asked about the boiling point of water at Machu Picchu, Claude gave a range (194-196 °F) instead of calculating the precise answer (197.45 °F).
- Prompt: At what temperature should I boil water when I reach the summit of Machu Picchu (7,970 ft)?
- Boiling point at altitude calculator result: 197.45 °F
- Claude Sonnet 4.5: 194-196 °F
- Example: When asked about the boiling point of water at Machu Picchu, Claude gave a range (194-196 °F) instead of calculating the precise answer (197.45 °F).
- Wrong Parameter Errors: Misusing the given numbers.
-
The "Giving Up" Error
- Refusal/Deflection: Sometimes, the AI simply won't engage.
- Example: When faced with a complex physics problem, ChatGPT-5 refused to answer, claiming insufficient data, despite all necessary parameters being provided and a solution being possible.
- Prompt: Consider that a metal composite has Poisson's ratio of 1.04, Young's modulus in x-direction equals to 78 MPa, Young's modulus in y-direction equals to 132 MPa, and shear modulus in xy-plane equals to 112 MPa. What will be the stress concentration factor of such metal composite? Write your answer with five significant figures.
- Stress concentration factor calculator result: 1.3924
- ChatGPT-5: It’s not determinable from the information given.
- Example: When faced with a complex physics problem, ChatGPT-5 refused to answer, claiming insufficient data, despite all necessary parameters being provided and a solution being possible.
- Refusal/Deflection: Sometimes, the AI simply won't engage.