In the last century, mathematicians developed a framework that describes the dynamics of a waiting line: learn the fundamentals of queueing theory with our queueing theory calculator.
Since humans started getting along in that thing we call society, they also started waiting. Waiting for their turn to talk, eat, pay taxes, you name it. With the growth of the population and the increasing complexity of our daily lives, we started waiting even more.
It's not surprising that someone developed an interest in analyzing and modeling the behavior of queues. Understanding how long it will take to clear a line of customers or how many checkouts to keep open during a busy afternoon is a real help in smoothing many time-consuming processes.
Now you can imagine why queueing theory is important: keep reading to learn more. In this article, you will discover:
- The fundamentals of queueing theory: what is queueing theory?
- The principal elements of a queue and the Kendall notation;
- The cornerstone of queues: the queue;
- Adding servers: the queue;
- How to use our queueing theory calculator, with examples; and
- Applications of the queueing theory.
This article is nothing but a dent in the surface of the intriguing framework of queueing theory. If interested, we invite you to expand from here! What are you waiting for? Pun intended. 😉
What is queueing theory?
You don't have to spend weeks on a thick book to understand what queueing theory is — though its mathematical description may get pretty long: we are talking of the same process of entering a waiting line — and waiting — to get access to a service. You do this every time you get groceries or go to the bank.
The queueing theory was developed by Agner Krarup Erlang in the early XX century while he was waiting in line at a slow local post office. No, sorry, while he was working on the analysis of telephone networks. The theory successfully developed in the following years, thanks to the pervasive nature of queues and the helpfulness of the results of the queueing models.
So, what exactly is the queueing theory? The queueing theory analyzes the behavior of a waiting line to make predictions about its future evolution. Some examples of what we can calculate with a queueing model are:
- The waiting and service time;
- The total number of customers in the queue;
- The utilization of the server.
And much more.
Queueing theory has deep roots in statistics and probability. The arrival and servicing of customers are, fundamentally, stochastic processes. However, when analyzing such processes over long times or far in the future, their implicit randomness somehow vanes: we talk then of the steady state of the process. A detailed description of the foundations of queueing theory requires a solid background in the mentioned field of maths: we will try to keep it low and focus on the calculations for the queueing theory models!
When do we use queueing theory?
Queueing theory has many applications, and not only where humans wait! The management of the take-offs and landings at a busy airport, the execution of programs on your computer, and the behavior of an automatized factory all benefit from a careful analysis of queues.
From calculating traffic density to graphing theory, queues are everywhere, from theoretical mathematics to our daily lives!
Speaking of...
What is a queue?
In the mathematical sense, a queue is a complex object modeled by a black box. In this black box, we identify two flows: one inbound and one outbound. What happens inside the box is unknown, but the outbound customers are happier than the inbound ones.

If we peek inside the box, we see a certain number of servers that process the request of the customers. Some are free — waiting to receive a customer, and some are currently busy. One way or the other, the queue moves on.
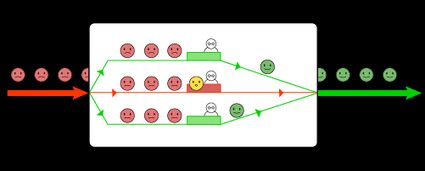
What matters to the modelization of a queue is usually the customers' waiting time. Say you want to optimize it or to find pitfalls that uselessly prolong it. Other goals are to optimize the "utilization" of servers or decrease the queue length.
Describing a queue in the mathematical sense requires understanding some basic concepts. Firstly, a queue is represented by states, each telling us the number of people in the queue, either waiting or being serviced.
With certain probability — a quick reminder that queues are rooted in the framework of stochastical processes — the customers arrive and receive the required service. This moves the queue: arrivals increase the state, and services reduce it to reach the state .
🙋 If you've already met Markov chains, then yes, the representation of a queue lives in this framework. We consider queues to be Markovian processes in a stable state.
States are related to probabilities, but the queue theory describes the time spent in a given state more than defining this quantity. An alternative explanation is the chance of having a specified number of customers in the queue: time and "occupation" are, surprisingly, equivalent!
Queueing discipline: who's going first?
The order in which customers receive service in a queue is the queueing discipline. The most common discipline is the first in, first out discipline (FIFO), where the customer priority depends on the time spent in the queue.
Other disciplines are:
- Last in first out (LIFO), where items entered last are the first ones to be serviced. Think of a pile of pancakes or things stuffed in a backpack. This discipline is rarely used when humans are involved: we let you guess why!
- Priority discipline happens when the servicing order depends on some defining factors. In the ER, the man with an alien poking out of his chest will pass before the one who hit his pinky on a corner: they may even use our injury severity score calculator to assess a patient's priority.
- Round robin servicing, where the customer receives service for a given time and can re-enter the queue; and
- Service in random order (SIRO), that no one likes.

Most models, and all the ones we will analyze here, use the FIFO discipline — it's the most reasonable!
Meet the servicing policies in other fields at Omni's fifo calculator and lifo calculator!
The Kendall notation: classifying queues
How do we identify a queue? David George Kendall answered this question by laying down a straightforward notation that helps to choose the right set of equations for each situation quickly. The basic Kendall notation consists of three symbols in the form:
Where:
- is the probability distribution for the intervals between customer arrivals;
- is the probability distribution of the servicing time; and
- is the number of servers.
and can assume various values (letters), the most important being:
- , standing for Exponential distribution;
- , standing for Erlang distribution;
- for any general probability distribution of which you know mean and variance.
You can expand the Kendall notation to include other parameters. The notation includes:
- the maximum number of customers accepted in the queue (think of the capacity of an office);
- the size of the customer population; and
- the queueing discipline.
The most commonly analyzed queue is the queue (exponential distribution for the intervals between arrivals and servicing times by a single server). We will describe it in detail. Other commonly studied queues are the and .
The M/M/1 queue: your first example of a queueing theory model
We can analyze some models now that you know what queueing theory is. Here we will deal with the simplest queueing model. Take a single queue with a single server, and assume that:
- The time intervals between successive customers' arrivals follow an exponential distribution; and
- The servicing times follow an exponential distribution.
Poisson and exponential probability distributions are closely related concepts. Considering a Poisson process (a stochastic process describing random occurrences of an event): the number of events in a given time follows the Poisson distribution. The interval between those events, on the other hand, follows the exponential distribution.
In the context of an queue, this means that the time of arrival of each customer is independent of the other (no rush hours or downtimes), and the time interval between arrivals, follows this distribution:
The servicer takes a specific time for each request, that doesn't depend on previous or future events (e.g., the service of a late customer won't go faster because dinner time approaches!). The distribution takes this form:
Arrival and service allow us to move the queue between states, balancing each other or prevailing; they make our system dance.
🙋 Queues are inherently memoryless: the past and future events (in our case, the arrival of a customer and the completion of a service) follow two types of processes defined by this lack of influence of previous states: the Markov chains and the exponential distributions.
If we move in the steady-state, we can define the two fundamental quantities we've just met in the formulas for the distributions:
- The arrival rate , which describes the number of customers entering the queue per unit of time; and
- The service rate , the number of serviced customers per unit of time.
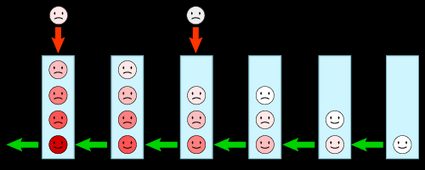
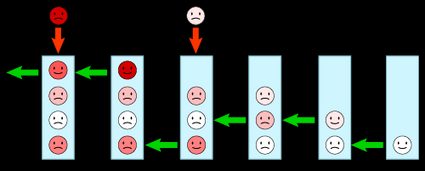
and describe how the queue moves between states, interplaying with the fraction of time spent in the state , (with the number of customers in the queue at that time). We follow these rules:
represents a queue with one customer receiving service, leaving it empty. It corresponds to the opposite process, a customer entering an empty queue ().
For further states, we find:
How do we find these relationships? By using the previously found equivalence, and an analysis of the queue representation, we can equate the sum of the "arrows" inbound and outbound from a given state. Take a look at the diagram below:
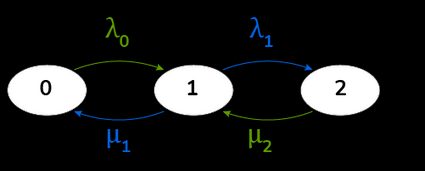
That's how the queue moves. By computing the ratio between the arrival rate and the service rate, we find the traffic intensity :
🙋 The only condition we need to state for an queue is that , which implies that the queue eventually dies out and doesn't accumulate infinite customers.
Let's analyze the performance measures of the queue. We start with the average number of customers, .
We can now use Little's law to derive the average time spent in the system, :
The time spent in the queue is of equal interest. We denote it as and calculate it again using Little's law, but this time starting from the number of customers in the queue :
The four queue equations we met define the fundamental quantities in every queueing theory model.
What else can be helpful in the analysis of an ? We can define the probability of no customers in the system, :
We calculate the probability of the presence of customers in the queue, by taking times :
What about the values of for any other ? The formula is straightforward, and it derives from multiple applications of the transition between states from the empty queue:
Now that we have analyzed the queue, we can move to slightly more complex models.
A new checkout opens: the M/M/s queues
We will now analyze an queue with several servers bigger than one. We need to introduce a few more quantities here.
is the number of servers in the system. Each serves independently, following the same exponential distribution and rate of service .
We redefine the server utilization as . You can think of as the maximum service rate. In fact, an queue is nothing but an queue with service rate .
Let's introduce one last quantity, (which corresponds to the server utilization in the queue), thus .
However, please pay attention to the behavior of the servicing process. In the queue, we can find situations where some servicers are simply... hanging out, waiting for a customer to arrive. We slightly tweak our definition of in this situation:
The steady-state probability of having zero customers in the queue depends, as you can imagine, on the number of servers. We calculate with the formula:
The number of customers in the queue and in the system, respectively and , are the results of the queue equations:
Let's calculate the waiting times. We do it similarly to the queue, but we need to modify them slightly.
The waiting time in the system and in the queue are:
We can introduce one last quantity specific for the queue: the probability of a customer joining the queue and finding no free servers. We call this quantity probability of customer delay, :
is a parameter we've already met, though slightly different:
Eventually, we can define the probability of the queue to be in the state : we met this quantity before. Since the behavior of this queue depends on the number of customers and servers:
Now, it's time to meet our queueing theory calculator!
How to use our queueing theory calculator
Our queueing theory calculator allows you to calculate the results of queues and queues.
The framework of queueing theory is rather complex: this short article is nothing but an introduction, and our calculator is pretty basic! You can explore it if you just found this exciting branch of mathematics or use it to check the results of your calculations (in particular for queues with multiple servers).
First, choose the queue you are interested in. Input the values you know; we will calculate the rest. Notice that certain operations are hard to invert: for an queue contains a summation and a factorial, and even with all the efforts, we wouldn't be able to use this value as an input. It is greyed out with the other "difficult" values in our queueing theory calculator.
FAQs
What is queueing theory?
Queueing theory is a mathematical framework created to explain waiting lines.
You need some fundamental elements to define a queue:
- An arrival statistics (how the queues grow);
- The servicing rate (how the queue shrinks); and
- The number of servers.
In the most common queue, both the intervals between successive arrivals and the servicing times are described by exponential distributions, and there is a single server. The corresponding model is the M/M/1 queue.
What is the condition for a queue to eventually end?
A queue ends if and only if the service rate exceeds the customers' arrival rate. This way, the servers allow the queue of customers to eventually deplete.
A good measure of this attitude is the traffic intensity, the ratio between arrival and servicing rate. The lower the rate, the easier the flow of the queue.
What is the average waiting time in an M/M/1 queue with ρ = 0.17 and λ = 0.03
6.83. To calculate this value, follow these steps:
- Find the servicing rate
μ:μ = λ/ρ = 0.03/0.17 = 0.17647. - Plug the appropriate values in the formula for the time in the system:
W = 1/(μ - λ):
W = 1/(μ - λ) = 1/(0.17647 - 0.03) = 6.83 - To find the value of the actual waiting time, multiply the result by
ρ = λ/μ:
Wq = ρ × W = 0.17 × 6.83 = 1.16
This time consider only the time you are standing in line.
What is the most common policy used to service a queue?
As you can imagine, the most common policy to service a queue is the first-in-first-out one. This method is applied in almost every system where humans queue, and for all the right reasons!
However, there are exceptions. In priority-based systems, this policy has many shortfalls. Similarly, the policy last-in-first-out appears when, for example, we are leaving a crowded bus. The answer is: it depends!