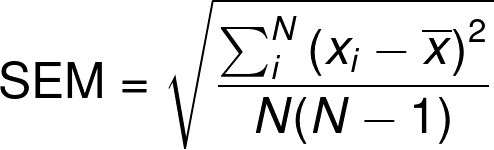
Welcome to the standard error calculator, also known as the standard error of the mean (SEM) calculator. This is a great tool that helps you estimate the standard error of the mean of any dataset in the blink of an eye.
If you've studied statistics at all, you've probably already heard of the mean, median, and mode, but do you know how to calculate the standard error? If not – this is the right place to begin!
In the article below, you can also find the equation of the standard error of the mean, as well as a comparison of standard error vs. standard deviation. There is no time to waste, let's go!
💡 Check also our mean absolute deviation calculator, which estimates the error using a slightly different approach.
What is a standard error?
To learn how to find a standard error, we first need to ask ourselves standard error of what?
In statistics, we can estimate the standard error of any parameter – a mean, a proportion, a difference of means, and many many more. Typically, if someone wants to know how to calculate the standard error, it's the standard error of the mean or SEM for short.
Great! So then, why do we want to know how to find the standard error?
Let's say we have a task to find the average height of adults within a country. Such measures usually form a normal distribution for large populations.
Ideally, we should measure everybody one by one, and eventually, we would get a precise, well-defined number. In practice, however, it's impossible from a time, money, and technical point of view, so we need to estimate such a value.
One approach is to take a relatively small group of people (a sample) and find their average height. It's almost certain that it won't be precisely the same as the one for the whole country. Still, we should be able to say that there is a high probability that the real result is within a range of values that we evaluated using the standard error. That's an example of a situation where this SEM calculator comes in handy!
💡 Omni's error propagation calculator will help you evaluate the total error when dealing with multiple variables.
Standard error formula
The equation of the standard error of the mean in its most compact form is:
where:
- is the ith measure;
- (x-bar) stands for the mean value of our dataset; and
- is the number of data points.
To get familiar with the standard error formula, it's a good practice to follow these steps:
-
Evaluate the mean value (). It's usually the arithmetic average.
-
Find the differences for every point.
-
Square the differences for each of the points separately, .
-
Add up all of the squared differences .
-
Divide the sum by the product .
-
Finally, work out the square root of this ratio.
As you can see, estimating the standard error of the mean for multiple points by hand can be really time-consuming. In such cases, using our standard error calculator is always a good idea, and you'll also avoid any mistakes!
💡 To express the standard error relative to the size of the estimate rather than in the original units, use our RSE calculator.
Standard error vs. standard deviation
In statistics, the standard deviation tells us about the variability of the respective measures from the mean. So what is the difference between standard deviation and standard error, then?
Simply speaking, the standard deviation is a parameter of a population (or a sample), while the standard error is an estimation of a particular value. In general, we can compute the standard error of any statistical value, but in most cases, we want to find the standard error of the mean.
To compare standard error vs. standard deviation, let's take a look at their formulas:
-
for a population, where is the variance of the set; or
-
for a sample, where is the estimate of the variance.
-
and stand for the mean and sample mean, respectively.
In other words, SEM measures the uncertainty in estimating the population mean. To combine the standard error with a confidence level and obtain an error bound, you can try the sampling error calculator.
🔎 Read more about standard deviation in Omni's standard deviation calculator.
Take a look at an example:
We want to estimate the average height of students in a school (a population). We take a group of 12 random pupils (a sample) whose heights (in cm) are 177, 182, 175, 194, 181, 177, 169, 180, 182, 186, 179, and 172.
The average height of this sample is x̄ = 179.5. Using our SEM calculator, you can find that the standard error of the mean equals SEM = 1.88. It tells us that the (real) mean height of students in this school is most likely between 177.62 and 181.38 (which is 179.5 ± 1.88).
At the same time, this sample's standard deviation is s = 6.52. This means that we can expect that the majority of students' heights (roughly 70%) to lie within the range [172.98, 186.02] (that is 179.5 ± 6.52).
How to find a standard error of the mean?
Let's say we have a set of ten different values related to the weight of balls taken randomly from a production line. The numbers are: [5.5, 5.8, 6.1, 5.4, 5.5, 5.4, 5.9, 5.6, 5.9, 5.5]. The question is: what is the standard error of the mean for these measures? Let's do it step by step:
-
Work out the mean value of this set. x̄ = (5.5+5.8+6.1+5.4+5.5+5.4+5.9+5.6+5.9+5.5) / 10 = 56.6/10 = 5.66.
-
Calculate the difference between every number and the mean (xᵢ - x̄): [-0.16, 0.14, 0.44, -0.26, -0.16, -0.26, 0.24, -0.6, 0.24, -0.16].
-
Square them: [0.0256, 0.0196, 0.1936, 0.0676, 0.0256, 0.0676, 0.0576, 0.0036, 0.0576, 0.0256].
-
Sum them up: 0.0256 + 0.0196 + 0.1936 + 0.0676 + 0.0256 + 0.0676 + 0.0576 + 0.0036 + 0.0576 + 0.0256 = 0.544.
-
Make a fraction from this value and 90 (that is N(N-1)=10×9): 0.544 / 90 = 0.0060.
-
Compute the square root of the latter, resulting in the standard error of the mean: SEM = √0.0060 = 0.078.
-
We can also write that our estimated mean in the form x̄ = 5.660 ± 0.078, taking two significant figures into account.
You can always check the result with our standard error calculator!
🙋 If you find this tool useful, our margin of error calculator will be a valuable extension on the topic.
By the way, have you heard about the skewness or mean absolute deviation? These are other parameters you can find while working with statistical data. Each of them carries additional information about your numbers!