The floating-point calculator is here to help you understand the IEEE754 standard for the floating-point format. It acts as a converter for floating-point numbers — it converts 32-bit floats and 64-bit floats from binary representations to real decimal numbers and vice versa.
💡 Are you looking to convert binary numbers to the decimal system? Perhaps you'd be interested in our binary calculator!
How to use the floating-point calculator
Before we get into the bits and bytes of the float32 and float64 number formats, let's learn how the floating-point calculator works. Just follow these easy steps:
-
If you want to convert the binary encoding of a floating-point number to the decimal number it represents, select
floating-point to numberat the top of the calculator. Then:-
Select the precision used. This determines how your binary representation will be interpreted.
-
Enter the floating-point number's binary digits. You can enter the sign, exponent, and fraction separately, or you can enter the entire bit-string in one go — select your preference in the
Bit input methoddropdown menu. -
The value stored in your float will be shown at the bottom of the calculator.
-
-
If you want to convert a value into its floating-point representation, select
number to floating-pointat the top of the calculator. Then:-
Enter your number in the field below that.
-
The IEEE754 floating-point binary and hexadecimal representations of both single- and double-precision floats will be shown below.
-
The floating-point calculator will also show you the actual value stored due to the loss of precision inherent to the floating-point format. The error due to this loss of precision will also be reported.
-
What is an IEEE754 floating-point number?
In computing, a floating-point number is a data format used to store fractional numbers in a digital machine. A floating-point number is represented by a series of bits (1s and 0s). Computers perform mathematical operations on these bits directly instead of how a human would do the math. When a human wants to read the floating-point number, a complex formula reconstructs the bits into the decimal system.
The IEEE754 standard (established in 1985 by the Institute of Electrical and Electronics Engineers) standardized the floating-point format and also defined how the format can be operated upon to perform math and other tasks. It's been widely adopted by hardware and software designers and has become the de facto standard for representing floating-point numbers in computers. When someone mentions "floating-point numbers" in the context of computing, they'd generally mean the IEEE754 data format.
💡 Computer performance (i.e., speed) can be measured by the number of floating-point operations it can do per second. This metric is called FLOPS and is crucial in fields of scientific computing.
The most well-known IEEE754 floating-point format (single-precision, or "32-bit") is used in almost all modern computer applications. The format is highly flexible: float32s can encode numbers as small as 1.4×10−45 and as large as 3.4×1038 (both positive and negative).
Besides single-precision, the IEEE754 standard also codifies double-precision ("64-bit" or float64), which can store numbers from 5×10−324 to 1.7×10308. Less commonly used IEEE754 formats include:
- Half-precision ("16-bit");
- Quadruple-precision ("128-bit"); and
- Octuple-precision ("256-bit").
💡 Technically, although IEEE754 only defines these formats, any arbitrary precision is possible — many older computers used 24-bit floating-point numbers!
However, a floating-point number is not just a number converted to the binary number system — it's much more complicated than that! Let's learn how the IEEE754 floating-point standard works.
How are real numbers stored with floating-point representation?
Any floating-point binary representation consists of three segments of bits: sign, exponent, and fraction.
- The sign (
S) indicates positive or negative; - The exponent (
E) raises 2 to some power to scale the number; and - The fraction (
F) determines the number's exact digits.
The segments' lengths and exact formula applied to S, E, and F to recreate the number depend on the format's precision.
When stored in memory, , , and are laid end-to-end to create the full binary representation of the floating-point number. In computer memory, it might look like this:
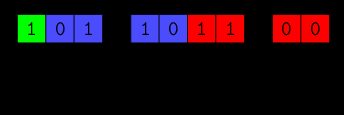
These bits are what the computer manipulates when arithmetic and other operations are performed. The computer never sees a number as its decimal digits — it only sees and works with these bits.
💡 The choice of precision depends on what its application requires. More precision means more bits and higher accuracy, but also bigger storage footprint and longer computation time.
Let's look at the two most commonly used floating-point formats: float32 and float64.
The single-precision 32-bit float format
float32 is the most commonly used of the IEEE754 formats. As suggested by the term "32-bit float", its underlying binary representation is 32 bits long. These are segmented as follows:
- 1 bit for the sign ();
- 8 bits for the exponent (); and
- 23 bits for the fraction ().
When it's stored in memory, the bits look like this:
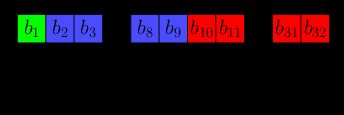
We can rewrite it as a binary string:
The real value that this 32-bit float stores can be calculated as:
where:
- is called the exponent bias and is inherent to the single-precision format;
- means that must be interpreted as if in base 2 or binary; and
- means to take the binary bits to and use it as the fractional part of to form a binary fraction. See our binary fraction calculator for help on that.
We can rewrite the formula better using , , and :
where
- ;
- ; and
- .
To let floating-point formats store really small numbers with high precision, and activates a separate formula. For float32, that formula is
Numbers created by this formula are called "subnormal numbers", while "normal numbers" are created using the previous formula.
There are other special cases, encoded by specific values for and :
Value | ||
|---|---|---|
Any | ||
means "not a number", which is returned when you divide by zero or perform impossible math using infinity. For the cases of and , the sign bit determines whether the number is positive or negative. And yes, negative zero is a thing!
An example
Let's convert the binary floating-point representation 01000001110111100000000000000000 to the real number it represents.
-
First, let's segment it into , , and :
-
-
Since , we use the normal number formula:
-
(so the number is positive!)
-
-
-
-
Combine the three multiplicands:
Want to see for yourself? Try this value in our floating-point calculator to see it in action!
Note that converted directly from binary to decimal is not , but . Quite the difference, wouldn't you say?
💡 Floating-point numbers' formula can be seen as a form of scientific notation, where the exponential aspect uses base 2. We can rewrite the example above as . See our scientific notation calculator for more information.
The double-precision 64-bit float format
The inner workings of the float64 data type are much the same as that of float32. All that differs are:
- The lengths of the exponent and fraction segments of the binary representation — in 64-bit floats, takes up 11 bits, and takes up 52.
- The exponent bias — in 64-bit floats, it's 1023 (whereas in 32-bit floats, it's 127).
The formulas for the reconstruction of 64-bit normal and subnormal floating-points are, therefore, respectively:
and
Because of the additional exponent and fraction bits compared to float32s, float64s can store much larger numbers and at much higher accuracy.
💡 All IEEE754 floating-point formats follow this pattern, with the biggest differences being the bias and the lengths of the segments.
How do I convert a number to floating-point?
To convert a decimal number to a floating-point representation, follow these steps:
- Convert the entire number to binary and then normalize it, i.e. write it in scientific notation using base 2.
- Truncate the fraction after the decimal point to the allowable fraction length.
- Extract the sign, exponent, and fraction segments.
Refer to the IEEE754 standard for more detailed instructions.
An example
Let's convert back to its floating-point representation.
-
Our integer part is , which in binary is . Our fraction part is . Let's convert it to a binary fraction:
So , and then . To normalize it, we rewrite it as:
-
- The digits after the decimal point are already a suitable length — for
float32, we'd be limited to 23 bits, but we have only five.
From the normalized rewrite, we can extract that:
- , since the number is positive;
- (we add because must be ); and
- (zeroes get padded on the right because we're dealing with fractional digits and not an integer).
Therefore, our floating-point representation is .
You can verify this result with our floating-point calculator!
Floating-point accuracy
Floating-point numbers cannot represent all possible numbers with complete accuracy. This makes intuitive sense for sufficiently large numbers and for numbers with an infinite number of decimals, such as pi () and Euler's number (). But did you know that computers cannot store a value as simple as with 100% accuracy? Let's look into this claim!
When you ask a computer to store as a float32, it will store this binary string:
00111101110011001100110011001101
If we convert that back to decimal with the floating-point formulas we learned above, we get the following:
That's a little bit more than ! The error (how far away the stored floating-point value is from the "correct" value of ) is .
Let's try to rectify this mistake and make the smallest change possible. Our stored number is a little too big, so let's change that last bit from a to a to make our float a little bit smaller. We're now converting:
00111101110011001100110011001100
And we've missed our mark of again! This time, the error is a little larger (). The first binary string that ended in 1 was even more correct than this one!
You may think, "what if we used more bits?" Well, if we were to do the same with the float64 format instead, we'd find the same problem, although less severe. converted to a 64-bit floating-point and back to decimal is , and the error here is . This is the higher accuracy of float64 in action, but the error is still not — the conversion is still not lossless.
This is, unfortunately, the drawback of the ubiquitous floating-point format — it's not 100% precise. Small bits of information get lost, and they can wreak havoc if not accounted for. The only numbers that can be stored perfectly as a float without any losses are powers of 2 scaled by integers because that's how the format stores numbers. All other numbers are simply approximated when stored as a floating-point number. But it's still the best we've got!
💡 Some operations are more resilient against precision loss. Try our condition number calculator to see how severely a loss of accuracy will affect matrix operations.
FAQs
Why do we use floating-point numbers?
The IEEE754 floating-point format standard enables efficient storage and processing of numbers in computers.
-
From a hardware perspective, many simplifications of floating-point operations can be made to significantly speed up arithmetic, thanks to the IEEE754 standard's specifications.
-
For software, floats are very precise and typically lose a few millionths (if not less) per operation, which enables high-precision scientific and engineering applications.
What is the floating-point representation of 12.25?
The floating-point representation of 12.25 is 01000001010001000000000000000000. Its sign is 0, its exponent is 100000102 = 130, and its fraction is 100010...0. Reconstructed to decimal, we get:
(−1)0 × 2(130−127) × (1.10001)2
= 1 × 23 × 1.53125
= 12.25