
Witamy w Omni kalkulatorze wartości p. Nigdy więcej nie będziesz już musiał(a) kłopotać się wyznaczaniem wartości p (p-wartości, ang. p-value), ponieważ nasze narzędzie przeliczy za ciebie wartość statystyki testowej na jednostronne i dwustronne wartości p dla wszystkich najpopularniejszych rozkładów: normalnego, t-Studenta, chi-kwadrat i F-Snedecora.
Choć wartość p pojawia się w najróżniejszych dziedzinach nauki, dla wielu osób to pojęcie wciąż jest nieco onieśmielające. Nie przejmuj się — w poniższym artykule wyjaśnimy nie tylko, czym w teorii jest wartość p, ale także jak poprawnie ją interpretować. Czy kiedykolwiek zastanawiało cię, jak ręcznie obliczać wartość p? Zaraz zobaczysz wszystkie niezbędne wzory!
🙋 Jeśli chcesz odświeżyć sobie podstawy statystyki, nasz kalkulator testowania hipotez 🇺🇸 to świetny punkt wyjścia.
📊 Wszystkie informacje o rzeczywistych danych statystycznych w jednym miejscu
Odkryj naszą pełną , która zawiera artykuły i raporty stworzone przez ekspertów — wszystko w jednym miejscu!
Najpopularniejsze artykuły:
Co to jest wartość p?
Formalnie, wartość p jest prawdopodobieństwem tego, że statystyka testowa przyjmie wartości co najmniej tak skrajne, jak wartość, którą przyjęła dla twojej próbki. Należy pamiętać, że prawdopodobieństwo to jest obliczane przy założeniu prawdziwości hipotezy zerowej H0!
Oznacza to, że wartość p odpowiada na następujące pytanie:
Zakładając, że żyjemy w świecie, w którym hipoteza zerowa jest prawdziwa, jak prawdopodobne jest, że test, który właśnie przeprowadzamy, wygeneruje dla nowej próbki wartość co najmniej tak skrajną jak ta, którą dostaliśmy dla dotychczasowej próbki?
Co oznacza skrajna wartość? Otóż określa to hipoteza alternatywna, zatem wartość p zależy też od rozważanej przez nas hipotezy alternatywnej: lewostronnej, prawostronnej lub dwustronnej. W poniższych wzorach S oznacza statystykę testową, x oznacza jej wartość uzyskaną dla danej próby, a Pr(zdarzenie | H0) to prawdopodobieństwo zdarzenia, obliczone przy założeniu, że H0 jest prawdziwa:
-
Test lewostronny: p-wartość = Pr(S ≤ x | H0)
-
Test prawostronny: p-wartość = Pr(S ≥ x | H0)
-
Test dwustronny:
p-wartość = 2 · min{Pr(S ≤ x | H0), Pr(S ≥ x | H0)}
(min{a,b} oznacza mniejszą spośród liczb a i b)
Jeśli rozkład statystyki testowej przy założeniu prawdziwości H0 jest symetryczny względem 0, to:
p-wartość = 2 · Pr(S ≥ |x| | H0)lub, równoważnie:
p-wartość = 2 · Pr(S ≤ -|x| | H0)
Rysunek wyjaśnia więcej niż tysiąc słów; postaramy się więc teraz zilustrować te definicje. Wykorzystamy fakt, że prawdopodobieństwo można zgrabnie przedstawić jako obszar pod krzywą gęstości danego rozkładu. Pokażemy dwa zestawy rysunków: jeden dla rozkładu symetrycznego, a drugi dla rozkładu skośnego (niesymetrycznego).
- Przypadek symetryczny: rozkład normalny:
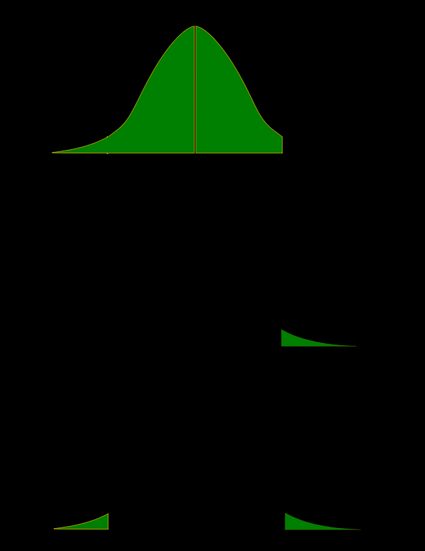
- Przypadek niesymetryczny: rozkład chi-kwadrat:
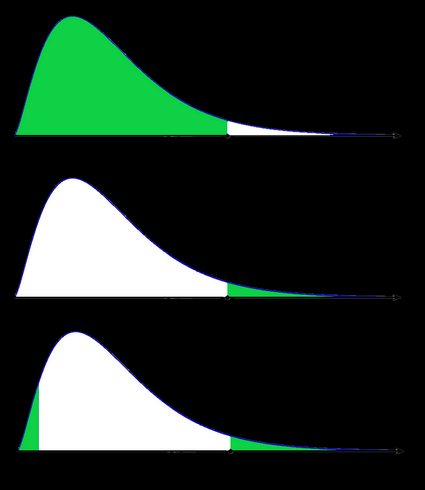
Na ostatnim rysunku (dwustronna wartość p dla rozkładu skośnego), zaznaczone pole pod krzywą po lewej stronie jest równe zaznaczonemu polu pod krzywą po prawej stronie.
Jak obliczyć wartość p na podstawie statystyki testowej?
Aby określić wartość p, trzeba znać rozkład statystyki testowej przy założeniu, że hipoteza zerowa jest prawdziwa. Następnie, za pomocą dystrybuanty tego rozkładu (cdf, ang. cummulative distribution function) możemy wyrazić prawdopodobieństwo tego, że statystyka testowa przyjmie wartości co najmniej tak skrajne jak wartość x, którą przyjęła dla badanej próby:
-
Test lewostronny:
p-wartość = cdf(x).
-
Test prawostronny:
p-wartość = 1 - cdf(x).
-
Test dwustronny:
p-wartość = 2 · min{cdf(x) , 1 - cdf(x)}.
Jeśli rozkład statystyki testowej (pod warunkiem prawdziwości H0) jest symetryczny względem 0, to wzór na dwustronną wartość p można uprościć do postaci p-wartość = 2 · cdf(-|x|), lub, równoważnie, p-wartość = 2 - 2 · cdf(|x|).
Rozkłady prawdopodobieństwa, które są najczęściej stosowane w testowaniu hipotez, mają zazwyczaj skomplikowane wzory cdf, a znalezienie wartości p ręcznie może nie być możliwe. Prawdopodobnie będziesz musiał skorzystać z komputera lub tabeli statystycznej, w której zebrano przybliżone wartości cdf.
Wiesz już, jak obliczyć wartość p, ale… dlaczego w ogóle musisz ją obliczyć? W testowaniu hipotez metoda wartości p jest alternatywą dla metody wartości krytycznej. Przypomnijmy, że to drugie podejście wymaga od badaczy wstępnego ustalenia poziomu istotności α, czyli prawdopodobieństwa odrzucenia hipotezy zerowej, gdy jest ona prawdziwa (czyli błędu pierwszego rodzaju). Po uzyskaniu wartości p wystarczy porównać ją z dowolną wartością α, aby szybko zdecydować, czy odrzucić hipotezę zerową na tym poziomie istotności, α. Szczegółowe informacje znajdziesz w następnej sekcji, w której wyjaśniamy, jak interpretować wartości p.
Dowiedz się więcej na ten temat w naszym artykule: Wartość p dla hipotezy zerowej: kiedy odrzucić hipotezę zerową 🇺🇸.
Jak interpretować wartość p
Jak wspomnieliśmy powyżej, wartość p jest odpowiedzią na następujące pytanie:
Zakładając, że żyję w świecie, w którym hipoteza zerowa jest prawdziwa, jak prawdopodobne jest, że dla innej próbki test, który przeprowadzam, wygeneruje wartość co najmniej tak ekstremalną, jak ta, którą zaobserwowałem dla próbki, którą już mam?
Co to oznacza dla Ciebie? Masz dwie opcje:
- Wysoka wartość p oznacza, że Twoje dane są wysoce zgodne z hipotezą zerową; i
- Mała wartość p dostarcza dowodów przeciwko hipotezie zerowej, ponieważ oznacza to, że Twój wynik byłby bardzo mało prawdopodobny, gdyby hipoteza zerowa była prawdziwa.
Może się jednak zdarzyć, że hipoteza zerowa jest prawdziwa, ale Twoja próba jest bardzo nietypowa! Wyobraź sobie na przykład, że badamy wpływ nowego leku i uzyskujemy wartość p wynoszącą 0,03. Oznacza to, że w 3% podobnych badań sam los mógłby nadal wytworzyć wartość statystyki testowej, którą uzyskaliśmy, lub wartość jeszcze bardziej ekstremalną, nawet jeśli lek w ogóle nie miałby żadnego efektu!
Na pytanie „co to jest wartość p” można również odpowiedzieć w następujący sposób: wartość p to najmniejszy poziom istotności, przy którym hipoteza zerowa zostałaby odrzucona. Jeśli więc chcesz podjąć decyzję dotyczącą hipotezy zerowej na pewnym poziomie istotności α, po prostu porównaj swoją wartość p z α:
- Jeśli wartość p ≤ α, to odrzucasz hipotezę zerową i akceptujesz hipotezę alternatywną; i
- Jeśli wartość p ≥ α, to nie masz wystarczających dowodów, aby odrzucić hipotezę zerową.
Oczywiście los hipotezy zerowej zależy od α. Na przykład, jeśli wartość p wynosiła 0,03, odrzucilibyśmy hipotezę zerową na poziomie istotności 0,05, ale nie na poziomie 0,01. Dlatego poziom istotności należy określić z góry, a nie dopasowywać go wygodnie po ustaleniu wartości p! Poziom istotności 0,05 jest najczęściej stosowaną wartością, ale nie ma w tym nic magicznego. Zawsze najlepiej jest podać wartość p i pozwolić czytelnikowi wyciągnąć własne wnioski. Aby dowiedzieć się więcej, przeczytaj nasz artykuł: Wartość p mniejsza niż 0,05 – co to oznacza? 🇺🇸.
Pamiętaj również, że wiedza specjalistyczna (i zdrowy rozsądek) są kluczowe. W przeciwnym razie, bezmyślnie stosując zasady statystyczne, można łatwo dojść do
Jak ręcznie obliczyć wartość p?
Jeśli chcesz określić wartość p ręcznie, wykonaj poniższe kroki:
- Zdefiniuj hipotezę zerową i alternatywną;
- Oblicz statystykę badania;
- Określ rozkład statystyki badania;
- Znajdź wartość p, korzystając z tabeli lub kalkulatora wartości p; oraz
- Porównaj wartość p z poziomem istotności.
Jak używać kalkulatora wartości p znając wartość statystyki testowej?
Nasz kalkulator wartości p jest do twojej dyspozycji, więc nie musisz już wyliczać jej przy użyciu tych wszystkich skomplikowanych wzorów! Wystarczy, że wykonasz następujące kroki:
-
Wybierz hipotezę alternatywną: dwustronną, prawostronną lub lewostronną.
-
Podaj rozkład statystyki testowej dla hipotezy zerowej: czy jest to rozkład N(0,1), t-Studenta, chi-kwadrat, czy F-Snedecora? Nie masz pewności? Czytaj dalej. Kolejne sekcje są poświęcone poszczególnym rozkładom.
-
W razie potrzeby określ liczbę stopni swobody rozkładu statystyki testowej.
-
Wprowadź wartość statystyki testowej dla twojej próbki danych.
-
Domyślnie poziom istotności w naszym kalkulatorze wynosi 0,05.
-
Nasz kalkulator określa wartość p na podstawie testu statystycznego i wyświetla opcje dotyczące hipotezy zerowej.
Jak znaleźć wartość p na podstawie wartości Z?
Przy użyciu dystrybuanty standardowego rozkładu normalnego, która jest tradycyjnie oznaczana literą Φ, wartość p możemy obliczyć na podstawie wartości Z (Z-score) za pomocą następujących wzorów:
-
Lewostronny test Z:
p-wartość = Φ(Zscore)
-
Prawostronny test Z:
p-wartość = 1 - Φ(Zscore)
-
Dwustronny test Z:
p-wartość = 2 · Φ(-|Zscore|)
lub
p-wartość = 2 - 2 · Φ(|Zscore|)
🙋 Aby dowiedzieć się więcej o tych testach, zajrzyj do Omni kalkulatora testu Z.
Wartości Z używamy, gdy rozkład statystyki testowej jest (przynajmniej w przybliżeniu) zgodny ze standardowym rozkładem normalnym N(0,1). Dzięki centralnemu twierdzeniu granicznemu możesz używać wartości Z jeśli masz dużą próbkę (co najmniej 50 punktów danych).
Test Z najczęściej odnosi się do testowania średniej populacji lub różnicy między średnimi dwóch populacji (na przykład między dwiema proporcjami). Testy Z można również spotkać w metodzie największej wiarygodności.

Wartość p z wyniku zmiennego: przykład
Możemy zbadać proces znajdowania wartości p ze zmiennej z na przykładzie. Załóżmy, że firma zajmująca się prawami konsumenta chce przetestować hipotezę zerową przy użyciu opakowań orzechów. Każda zwykła paczka orzechów zawiera dokładnie 78 orzechów, a firma może przetestować to twierdzenie przeciwko hipotezie zerowej, która mówi, że paczka orzechów nie zawiera 78 orzechów.
Biorąc pod uwagę, że w próbie 100 paczek średnia ilość orzechów wynosi 76 z odchyleniem standardowym populacji 13,5, a średnia populacji wynosi 80. Czy test dwustronny dostarcza wystarczających dowodów, aby odrzucić hipotezę zerową?
Aby znaleźć odpowiedź, obliczmy zmienną z, ustawiając: , , i . Teraz możemy zastąpić te parametry we wzorze na zmienną z:
Z tabeli zmiennej z możemy zweryfikować, że Φ(2,96) = 0,0015, zatem wartość p = 2 ⋅ 0,0015 = 0,003.
Ponieważ 0,003<0,05, hipoteza zerowa jest istotna statystycznie.
Jak znaleźć wartość p dla testu t?
Aby wyliczyć wartość p na podstawie t-score (czyli wartości statystyki testowej o rozkładzie t-Studenta), użyj następujących wzorów. Przez cdft,d oznaczamy dystrybuantę rozkładu t-Studenta o d stopniach swobody:
-
Lewostronny test t:
p-wartość = cdft,d(tscore)
-
Prawostronny test t:
p-wartość = 1 - cdft,d(tscore)
-
Dwustronny test t:
p-wartość = 2 · cdft,d(-|tscore|)
lub
p-wartość = 2 - 2 · cdft,d(|tscore|)
Użyj testu t, gdy statystyka testowa ma rozkład t-Studenta. Rozkład ten ma kształt podobny do rozkładu normalnego N(0,1) (krzywa dzwonowa), ale ma cięższe ogony (tzn. wartości krańcowe są bardziej prawdopodobne niż w N(0,1)) — dokładny kształt rozkładu t-Studenta zależy od parametru zwanego stopniami swobody. Jeśli liczba stopni swobody jest duża (>30), co zwykle ma miejsce w przypadku dużych próbek, to rozkład t-Studenta jest w praktyce nieodróżnialny od N(0,1).

Najpopularniejsze testy t badają średnią populacji o nieznanym odchyleniu standardowym lub też różnicę średnich dla dwóch populacji z nieznanymi (równymi lub różnymi) odchyleniami standardowymi. Istnieje również test t dla sparowanych (zależnych) próbek.
🙋 Aby uzyskać więcej informacji na temat tych testów, zajrzyj do naszego kalkulatora testu t-Studenta.
Wartość p dla testu chi-kwadrat (χ²-score)
Użyj opcji test χ² gdy wykonujesz test, w którym statystyka testowa ma rozkład chi-kwadrat.
Rozkład ten ma np. suma kwadratów zmiennych losowych, z których każda ma rozkład normalny N(0,1). Pamiętaj, aby sprawdzić liczbę stopni swobody rozkładu χ² twojej statystyki testowej!

Jak znaleźć wartość p znając χ²-score? Można to zrobić za pomocą poniższych wzorów, w których cdfχ²,d oznacza dystrybuantę rozkładu χ² o d stopniach swobody:
-
Lewostronny test χ²:
p-wartość = cdfχ²,d(χ²score)
-
Prawostronny test χ²:
p-wartość = 1 - cdfχ²,d(χ²score)
Pamiętaj, że testy χ² zgodności i niezależność są testami prawostronnymi! (zob. niżej)
-
Dwustronny test χ²:
p-wartość = 2 · min{cdfχ²,d(χ²score), 1 - cdfχ²,d(χ²score)}(min{a,b} oznacza mniejszą z liczb a i b)
Najpopularniejsze testy prowadzące do otrzymania χ²-score to:
-
Testowanie, czy wariancja danych z rozkładu normalnego ma pewną z góry określoną wartość. W tym przypadku statystyka testowa ma rozkład χ² o n - 1 stopniach swobody, gdzie n jest wielkością próby. Może to być test jednostronny lub dwustronny.
-
Test zgodności rozkładów (dopasowania) sprawdza, czy rozkład empiryczny (próby) zgadza się z pewnym oczekiwanym rozkładem prawdopodobieństwa. W tym przypadku statystyka testowa ma rozkład χ² o k - 1 stopniach swobody, gdzie k jest liczbą klas, na które podzielona jest próba. Jest to test prawostronny.
-
Test niezależności służy do określenia, czy istnieje statystycznie istotny związek między dwiema zmiennymi. Statystyka testowa opiera się na tabeli krzyżowej i ma rozkład χ² o (r - 1)(c - 1) stopniach swobody, gdzie r to liczba wierszy, a c to liczba kolumn w tabeli krzyżowej. Jest to test prawostronny.
Wartość p dla rozkładu F
Wreszcie, opcja wartości F powinna być używana podczas wykonywania testu, w którym statystyka testowa jest zgodna z rozkładem F, znanym również jako rozkład Fishera-Snedecora. Dokładny kształt rozkładu F zależy od dwóch typów stopni swobody.

Aby zobaczyć, skąd pochodzą te stopnie swobody, rozważmy niezależne zmienne losowe X i Y, które obie mają rozkład χ² z odpowiednio d1 i d2 stopniami swobody. W takim przypadku stosunek (X/d1)/(Y/d2) jest zgodny z rozkładem F, z (d1, d2) stopniami swobody. Z tego powodu dwa parametry d1 i d2 są również nazywane licznikiem i mianownikiem stopni swobody.
Wartość p z wyniku F jest określona przez następujące wzory, gdzie cdfF,d1,d2 oznacza funkcję skumulowanego rozkładu rozkładu F, z (d1, d2) stopniami swobody:
-
Lewostronny test F:
p-wartość = cdfF,d1,d2(Fscore)
-
Prawostronny test F:
p-wartość = 1 - cdfF,d1,d2(Fscore)
-
Dwustronny test F:
p-wartość = 2 · min{cdfF,d1,d2(Fscore), 1 - cdfF,d1,d2(Fscore)}
(Przez min{a,b} oznaczamy mniejszą z liczb a i b)
Poniżej wymieniamy najważniejsze testy, które dają wyniki F. Wszystkie z nich są testami prawostronnymi.
-
Test na równość wariancji w dwóch populacjach o rozkładzie normalnym. Jego statystyka testowa jest zgodna z rozkładem F z (n - 1, m - 1) stopniami swobody, gdzie n i m są odpowiednimi rozmiarami próbek.
-
ANOVA jest używana do testowania równości średnich w trzech lub więcej grupach, które pochodzą z normalnie rozłożonych populacji o równych wariancjach. Otrzymujemy rozkład F z (k - 1, n - k) stopniami swobody, gdzie k to liczba grup, a n to całkowita wielkość próby (we wszystkich grupach razem).
-
Test na ogólną istotność analizy regresji. Statystyka testowa ma rozkład F z (k - 1, n - k) stopniami swobody, gdzie n jest wielkością próby, a k jest liczbą zmiennych (wliczając wyraz wolny).
Po potwierdzeniu zależności liniowej w próbce danych za pomocą powyższego testu, można obliczyć współczynnik determinacji, R2, który wskazuje siłę tej zależności. Można to zrobić ręcznie lub skorzystać z naszego kalkulatora współczynnika determinacji 🇺🇸.
-
Test do porównania dwóch zagnieżdżonych modeli regresji. Statystyka testowa jest zgodna z rozkładem F z (k2 - k1, n - k2) stopniami swobody, gdzie k1 i k2 to liczba zmiennych odpowiednio w mniejszym i większym modelu, a n to wielkość próby.
Można zauważyć, że test F ogólnej istotności jest szczególną formą testu F do porównywania dwóch modeli zagnieżdżonych: testuje on, czy nasz model radzi sobie istotnie lepiej niż model bez zmiennych objaśniających (tj. model zawierający tylko wraz wolny).
FAQs
Czy p-wartość może być ujemna?
Nie, wartość p nie może być ujemna. Wynika to z faktu, że prawdopodobieństwa nie mogą być ujemne, a wartość p jest prawdopodobieństwem tego, że statystyka testowa spełnia pewne określone warunki.
Co oznacza duża wartość p?
Duża p-wartość (p-value) oznacza, że przy założeniu prawdziwości hipotezy zerowej jest bardzo prawdopodobne, że dla innej próbki statystyka testowa wygeneruje wartość co najmniej tak skrajną, jak ta uzyskana dla badanej próbki. Wysoka p-wartość nie pozwala na odrzucenie hipotezy zerowej.
Co oznacza mała wartość p?
Mała p-wartość (p-value) oznacza, że przy założeniu prawdziwości hipotezy zerowej jest mało prawdopodobne, że dla innej próbki statystyka testowa przyjmie wartość co najmniej tak skrajną, jak ta zaobserwowana dla badanej próbki. Mała p-wartość przemawia na korzyść hipotezy alternatywnej — pozwala odrzucić hipotezę zerową i przyjąć hipotezę alternatywną.