Willkommen bei unserem p-Wert-Rechner! Ab jetzt wirst dich nie wieder fragen müssen, wie du den p-Wert berechnest. Du kannst hier die einseitigen und zweiseitigen p-Werte für Teststatistiken der gängigsten Verteilungen bestimmen: Normalverteilung, studentsche t-Verteilung, Chi-Quadrat und F-Verteilung (Fischer-Snedecor-Verteilung).
Das Konzept der p-Werte mag etwas einschüchternd wirken, es ist in der Wissenschaft jedoch allgegenwärtig. Keine Sorge – in diesem Artikel erklären wir nicht nur, was der p-Wert ist und wie er berechnet wird, sondern auch wie er richtig interpretiert wird. Wolltest du schon immer wissen, wie du den p-Wert handschriftlich berechnen kannst? Auch dafür liefern wir dir alle notwendigen Formeln!
🙋 Wenn du einige Grundlagen in Statistik auffrischen möchtest, ist unser Rechner für die Normalverteilung ein hervorragender Ausgangspunkt.
📊 Dein Hub für Statistiken aus der Praxis
Entdecke unsere vollständige mit Expertenartikeln und Berichten – alles an einem Ort!
Beliebte Artikel:
Was ist der p-Wert?
Formal ist der p-Wert die Wahrscheinlichkeit, dass die Teststatistik Werte erzeugt, die mindestens so extrem sind wie der Wert, den er für deine Stichprobe erzeugt. Es ist wichtig zu wissen, dass diese Wahrscheinlichkeit unter der Annahme berechnet wird, dass die Nullhypothese H0 wahr ist!
Intuitiver ausgedrückt, beantwortet der p-Wert die Frage:
Angenommen, ich lebe in einer Welt, in der die Nullhypothese zutrifft, wie wahrscheinlich ist es, dass der Test, den ich durchführe, bei einer anderen Stichprobe einen Wert erzeugt, der mindestens so extrem ist wie der, den ich bei der mir bereits vorliegenden Stichprobe beobachtet habe?
Es ist die Alternativhypothese, die bestimmt, was „extrem“ tatsächlich bedeutet, sodass der p-Wert von der angegebenen Alternativhypothese abhängt: linksseitig, rechtsseitig oder zweiseitig. In den nachstehenden Formeln steht S für eine Teststatistik, x für den Wert, den sie für eine bestimmte Stichprobe ergibt, und Pr(Ereignis | H0) ist die Wahrscheinlichkeit eines Ereignisses, wenn wir annehmen, dass H0 wahr ist:
-
linksseitiger Test: p-Wert = Pr(S ≤ x | H0)
-
rechtsseitiger Test: p-Wert = Pr(S ≥ x | H0)
-
zweiseitiger Test:
p-Wert = 2 ∙ min{Pr(S ≤ x | H0), Pr(S ≥ x | H0)}
(Mit min{a,b} bezeichnen wir die kleinere der Zahlen a und b.)
Wenn die Verteilung der Tesstatistik unter der Annahme von H0 symmetrisch um 0 ist, dann ist:
p-Wert = 2 ∙ Pr(S ≥ |x| | H0)
beziehungsweise:
p-Wert= 2 ∙ Pr(S ≤ -|x| | H0)
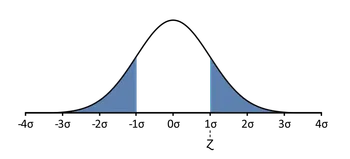
Da ein Bild mehr sagt als tausend Worte, lass uns also diese Definitionen veranschaulichen. Dabei nutzen wir die Tatsache, dass die Wahrscheinlichkeit als Fläche unter der Dichtekurve für eine bestimmte Verteilung dargestellt werden kann. Wir schauen uns zwei Abbildungen an: eine für eine symmetrische Verteilung und die andere für eine schiefe (unsymmetrische) Verteilung.
- Symmetrische Verteilung: Normalverteilung:
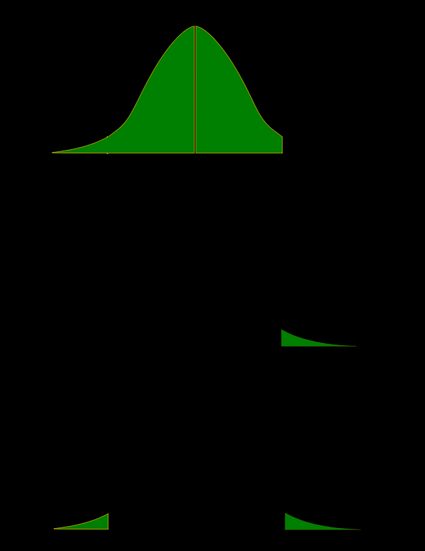
- unsymmetrische Verteilung: Chi-Quadrat-Verteilung:
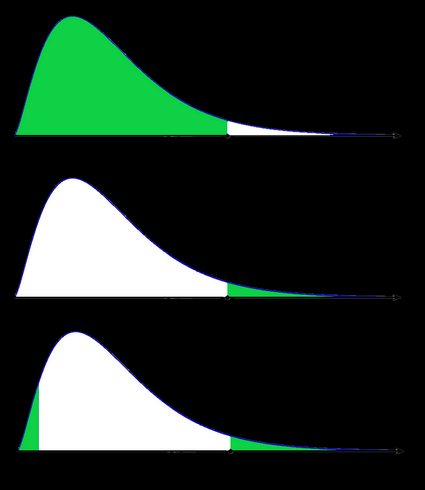
Auch in der letzten Abbildung (zweiseitiger p-Wert für schiefe Verteilung) ist die Fläche der linken Seite gleich der Fläche der rechten Seite.
Wie berechne ich den p-Wert aus der Teststatistik?
Um den p-Wert zu bestimmen, musst du die Verteilung deiner Teststatistik unter der Annahme, dass die Nullhypothese wahr ist, kennen. Dann kann diese Verteilung mithilfe der Verteilungsfunktion P die Wahrscheinlichkeit ausdrücken, dass die Teststatistik mindestens so extrem ist wie ihr Wert x für die Stichprobe:
-
linksseitiger Test:
p-Wert = P(x).
-
rechtsseitiger Test:
p-Wert = 1 - P(x).
-
zweiseitiger Test:
p-Wert = 2 ∙ min{P(x), 1 - P(x)}.
Wenn es sich, unter der Annahme von H0, um die Kurve einer Normalverteilung handelt, dann kann der zweiseitige p-Wert vereinfacht ausgedrückt werden als: p-Wert = 2 ∙ P(-|x|), oder p-Wert = 2 - 2 ∙ P(|x|).
Die für Hypothesentest am weitesten verbreiteten Wahrscheinlichkeitsverteilungen haben in der Regel komplizierte Formeln für die Verteilungsfunktion, und es ist oft nicht möglich, den p-Wert handschriftlich zu ermitteln. Wahrscheinlich wirst du zur Berechnung dieser, auf spezielle Software oder statistische Tabellen zurückgreifen müssen, in der ungefähre Werte für die Verteilungsfunktionen zusammengestellt sind.
Nun weißt du, wie der p-Wert berechnet wird, aber... wozu musst du diese Zahl überhaupt kennen? Bei der Hypothesenprüfung ist die Berechnung des p-Wertes eine Alternative zur Berechnung des kritischen Wertes. Bei letzterem wird mit dem Signifikanzniveau α gearbeitet, d. h. die Wahrscheinlichkeit, dass die Nullhypothese abgelehnt wird, obwohl sie wahr ist (d. h. Typ I -Fehler). Sobald du den p-Wert berechnet hast, brauchst du ihn nur mit einem gegebenen α zu vergleichen, um schnell entscheiden zu können, ob die Nullhypothese auf diesem Signifikanzniveau α abgelehnt werden sollte oder nicht. Einzelheiten dazu findest du im nächsten Abschnitt, in dem wir erklären, wie p-Werte interpretieren werden.
Erfahre mehr darüber in unserem Artikel: p-Wert für die Nullhypothese: Wann die Nullhypothese abgelehnt wird 🇺🇸.
Wie wird der p-Wert interpretiert?
Wie wir bereits erwähnt haben, ist der p-Wert die Antwort auf die folgende Frage:
Angenommen, ich lebe in einer Welt, in der die Nullhypothese gilt: Wie wahrscheinlich ist es dann, dass der Test, den ich durchführe, bei einer anderen Stichprobe einen Wert ergibt, der mindestens so extrem ist wie der, den ich bei der Stichprobe, die ich bereits habe, beobachtet habe?
Was bedeutet das für dich? Nun, du hast zwei Möglichkeiten:
- Ein hoher p-Wert bedeutet, dass deine Daten in hohem Maße mit der Nullhypothese vereinbar sind, und
- Ein kleiner p-Wert spricht gegen die Nullhypothese. Er bedeutet, dass dein Ergebnis sehr unwahrscheinlich ist, wenn die Nullhypothese wahr wäre.
Es kann aber auch vorkommen, dass die Nullhypothese zutrifft, deine Stichprobe aber sehr ungewöhnlich (ein Ausreißer) ist! Stell dir vor, du untersuchst z. B. die Wirkung eines neuen Medikaments und erhältst einen p-Wert von 0,03. Das bedeutet, dass in 3% ähnlicher Studien der Zufall allein den Wert der Teststatistik, den wir erhalten haben, oder einen noch extremeren Wert hervorbringen könnte, selbst wenn das Medikament überhaupt keine Wirkung hätte!
Die Frage „Was ist der p-Wert?“ kann auch wie folgt beantwortet werden: Der p-Wert ist das kleinste Signifikanzniveau, bei dem die Nullhypothese abgelehnt werden kann. Wenn du also bei einem bestimmten Signifikanzniveau α eine Entscheidung über die Nullhypothese treffen möchtest, vergleiche einfach deinen p-Wert mit α:
- wenn p-Wert ≤ α, dann solltest du die Nullhypothese ablehnen und die Alternativhypothese annehmen, und
- wenn p-Wert ≥ α, dann hast du nicht genug Beweise, um die Nullhypothese ablehnen zu können und solltest die annehmen.
Es ist klar, dass das Schicksal der Nullhypothese von α abhängt. Wenn der p-Wert beispielsweise 0,03 beträgt, würden wir die Nullhypothese bei einem Signifikanzniveau von 0,05 verwerfen, aber nicht bei einem Signifikanzniveau von 0,01. Aus diesem Grund sollte das Signifikanzniveau im Voraus festgelegt werden und nicht erst nach der Ermittlung des p-Wertes angepasst werden! Ein Signifikanzniveau von 0,05 ist der gebräuchlichste Wert, er hat aber nichts magisches an sich. . Es ist immer am besten, den p-Wert anzugeben und es dem Leser zu überlassen, seine eigenen Schlussfolgerungen zu ziehen. Um noch mehr darüber zu erfahren, kannst du unseren Artikel lesen: Ein p-Wert kleiner als 0,05 – Was bedeutet das? 🇺🇸.
Denke auch daran, dass Fachwissen (und gesunder Menschenverstand) entscheidend sind. Andernfalls kannst du bei der gedankenloser Anwendung statistischer Prinzipien leicht zu dem Fazit kommen, dass die Ergebnisse .
Wie kann ich den p-Wert per Hand berechnen?
Wenn du den p-Wert von Hand bestimmen möchtest, befolge die folgenden Schritte:
- Bestimme Null- und Alternativhypothese;
- Berechne die Test-Statistik;
- Bestimme die Verteilung der Test-Statistiken;
- Ermittle den p-Wert mithilfe einer Tabelle oder dieses p-Wert-Rechners; und
- Vergleiche den p-Wert mit dem Signifikanzniveau.
Wie wird der p-Wert einer Teststatistik mit dem p-Wert-Rechner ermittelt?
Mit unserem p-Wert-Rechner brauchst du dich nicht mehr zu fragen, wie du den p-Wert all dieser komplizierten Teststatistiken ermitteln kannst! Hier sind die Schritte, die du befolgen musst:
-
Wähle die Alternativhypothese: zweiseitig, rechtsseitig oder linksseitig.
-
Gib die Verteilung deiner Teststatistik unter Annahme der Nullhypothese an: ist es N(0,1), t-Student, Chi-Quadrat oder Fischer-Snedecor? Wenn du dir nicht sicher bist, sieh in den folgenden Abschnitten nach, die sich mit diesen Verteilungen befassen.
-
Gib, wenn erforderlich, die Freiheitsgrade der Verteilung der Teststatistik an.
-
Gib den Wert der Teststatistik an, der für deine Datenstichprobe berechnet wurde.
-
Das Signifikanzniveau ist standardmäßig auf 0,05 eingestellt.
-
Unser Rechner ermittelt aus der Teststatistik den p-Wert und gibt die Entscheidung über die Nullhypothese an. Das Signifikanzniveau ist standardmäßig auf 0,05 eingestellt.
Wie finde ich den p-Wert aus dem z-Wert?
In Bezug auf die kumulative Verteilungsfunktion (P) der Standardnormalverteilung, mit Φ bezeichnet, wird der p-Wert durch die folgenden Formeln angegeben:
-
linksseitiger z-Test:
p-Wert = Φ(ZWert)
-
rechtsseitiger z-Test:
p-Wert = 1 - Φ(ZWert)
-
zweiseitiger z-Test:
p-Wert = 2 ∙ Φ(-|ZWert|)
oder
p-Wert = 2 - 2 ∙ Φ(|ZWert|)
🙋 Wenn du mehr über Z-Tests erfahren möchtest, schaue dir den Z-Test Rechner von Omni an.
Wir verwenden den z-Wert, wenn die Teststatistik ungefähr der Standardnormalverteilung N(0,1) folgt. Dank des zentralen Grenzwertsatzes kannst du dich auf die Annäherung verlassen, wenn du einen großen Stichprobeumfang hast (z. B. mindestens 50 Datenpunkte), die du dann als Normalverteilung behandelst.
Ein z-Test bezieht sich meistens auf den Test des Mittelwerts der Grundgesamtheit oder den Unterschied zwischen zwei Mittelwerten der Grundgesamtheit, insbesondere zwischen zwei Proportionen. Du findest z-Tests auch bei Maximum-Likelihood-Schätzungen.

P-Wert aus dem z-Wert: ein Beispiel
Betrachten wir die Ermittlung des p-Wertes aus dem Z-Wert anhand eines Beispiels. Nehmen wir an, ein Verbraucherschutzunternehmen möchte die Nullhypothese anhand von Nusspackungen testen. Jede normale Nusspackung hat genau 78 Nüsse, und das Unternehmen kann diese Annahme gegen die Nullhypothese testen, die besagt, dass die Nusspackung keine 78 Nüsse enthält.
Wenn man bedenkt, dass in einer Stichprobe von 100 Packungen die durchschnittliche Menge an Nüssen 76 beträgt, mit einer Standardabweichung von 13,5, und der Mittelwert der Population 80 ist – bietet dann ein zweiseitiger Test genügend Beweise, um die Nullhypothese zu verwerfen?
Um die Antwort zu finden, lass uns den z-Wert berechnen: , , und . Nun können wir diese Parameter in die Formel für den Z-Wert einsetzen:
Anhand einer Z-Wert-Tabelle können wir überprüfen, dass Φ(2,96) = 0,0015, also p-Wert = 2 ∙ 0,0015 = 0,003.
Da 0,003<0,05, ist die Nullhypothese statistisch signifikant.
Wie finde ich den p-Wert aus dem t-Wert?
Der p-Wert aus dem t-Wert ergibt sich aus den folgenden Formeln, in denen Pt,d für die kumulative Verteilungsfunktion der studentschen t-Verteilung mit f Freiheitsgraden steht:
-
linksseitiger t-Test:
p-Wert = Pt,f(tWert)
-
rechtsseitiger t-Test:
p-Wert = 1 - Pt,f(tWert)
-
zweiseitiger t-Test:
p-Wert = 2 ∙ Pt,f(-|tWert|)
oder
p-Wert = 2 - 2 ∙ Pt,f(|tWert|)
Verwende die Option t-Wert, wenn deine Teststatistik der studentschen t-Verteilung folgt. Diese Verteilung hat eine ähnliche Form wie N(0,1) (glockenförmig und symmetrisch), hat aber stärkere Ränder – die genaue Form hängt von der Größe der Freiheitsgrade ab. Wenn die Anzahl der Freiheitsgrade groß ist (> 30), was in der Regel bei großen Stichprobenumfängen der Fall ist, ist die studentsche t-Verteilung praktisch nicht von der Normalverteilung N(0,1) zu unterscheiden.

Meistens werden t-Tests für die Mittelwerte von Populationen mit einer unbekannten Standardabweichung der Population oder für die Differenz zwischen den Mittelwerten zweier Populationen mit entweder gleichen oder ungleichen, aber unbekannten Standardabweichungen der Population verwendet. Es gibt auch einen t-Test für gepaarte (abhängige) Stichproben.
🙋 Um mehr über die t-Statistik zu erfahren, schaue dir unseren t-Test Rechner genauer an.
Wie finde ich den p-Wert aus dem Chi-Quadrat-Wert (χ²-Wert)?
Verwende die Option χ²-Wert, wenn du einen Test durchführst, bei dem die Teststatistik der χ²-Verteilung folgt.
Diese Verteilung ergibt sich zum Beispiel, wenn du die Summe der quadrierten Variablen nimmst, die alle der Normalverteilung N(0,1) folgen. Vergiss nicht, die Anzahl der Freiheitsgrade der χ²-Verteilung deiner Teststatistik zu überprüfen!

Wie kann der p-Wert aus dem Chi-Quadrat-Ergebnis ermittelt werden? Das kannst du mithilfe der folgenden Formeln tun, in denen Pχ²,f die kumulative Verteilungsfunktion der χ²-Verteilung mit f Freiheitsgraden bezeichnet:
-
linksseitiger χ²-Test:
p-Wert = Pχ²,f(χ²Wert)
-
rechtsseitiger χ²-Test:
p-Wert = 1 - Pχ²,f(χ²Wert)
Denke daran, dass χ²-Tests für Anpassungsgüte und Unabhängigkeit rechtsseitige Tests sind! (siehe unten)
-
zweiseitiger χ²-Test:
p-Wert = 2 ∙ min{Pχ²,f(χ²Wert), 1 - Pχ²,f(χ²Wert)}
(Mit min{a,b} bezeichnen wir die kleinere der Zahlen a und b.)
Die beliebtesten Tests, die zu einem χ²-Wert führen, sind die folgenden:
-
Test, ob die Varianz von normalverteilten Daten einen bestimmten Wert hat. In diesem Fall hat die Teststatistik die χ²-Verteilung mit n - 1 Freiheitsgraden, wobei n der Stichprobenumfang ist. Es kann sich um einen einseitigen oder zweiseitigen Test handeln.
-
die Anpassungsgüte prüft, ob die empirische (Stichproben-)Verteilung mit einer erwarteten Wahrscheinlichkeitsverteilung übereinstimmt. In diesem Fall folgt die Teststatistik der χ²-Verteilung mit k - 1 Freiheitsgraden, wobei k die Anzahl der Klassen ist, in welche die Stichprobe unterteilt wird. Es handelt sich um einen rechtsseitigen Test.
-
der Unabhängigkeitstest wird verwendet, um festzustellen, ob eine statistisch signifikante Beziehung zwischen zwei Variablen besteht. In diesem Fall basiert die Teststatistik auf der Kontingenztabelle und folgt der χ²-Verteilung mit (r - 1)(c - 1) Freiheitsgraden, wobei r die Anzahl der Zeilen und c die Anzahl der Spalten der Kontingenztabelle ist. Auch dies ist ein rechtsseitigen Test.
Wie finde ich den p-Wert aus dem F-Wert?
Schließlich sollte die Option F-Wert verwendet werden, wenn du einen Test durchführst, bei dem die Teststatistik der F-Verteilung folgt, auch als Fisher-Snedecor-Verteilung bekannt. Die genaue Form einer F-Verteilung hängt von zwei Freiheitsgraden ab.

Um zu sehen, woher diese Freiheitsgrade kommen, betrachte die unabhängigen Zufallsvariablen X und Y, die beide den χ²-Verteilungen mit f1 bzw. f2 Freiheitsgraden folgen. In diesem Fall folgt das Verhältnis (X/f1)/(Y/f2) der F-Verteilung mit (f1, f2) Freiheitsgraden. Aus diesem Grund werden die beiden Parameter f1 und f2 auch Freiheitsgrade des Zählers und Nenners genannt.
Der p-Wert aus dem F-Wert ergibt sich aus den folgenden Formeln, wobei PF,f1,f2 die kumulative Verteilungsfunktion der F-Verteilung mit (f1, f2) Freiheitsgraden bezeichnet:
-
linksseitiger F-Test:
p-Wert = PF,f1,f2(FWert)
-
rechtsseitiger F-Test:
p-Wert = 1 - PF,f1,f2(FWert)
-
zweiseitiger F-Test:
p-Wert = 2 ∙ min{PF,f1,f2(FWert), 1 - PF,f1,f2(FWert)}
(Mit min{a,b} bezeichnen wir die kleinere der Zahlen a und b.)
Im Folgenden listen wir die wichtigsten Tests auf, die F-Werte ergeben. Alle Tests sind rechtsseitig.
-
Ein Test für die Gleichheit der Varianzen in zwei normalverteilten Populationen. Seine Teststatistik folgt der F-Verteilung mit (n - 1, m - 1) Freiheitsgraden, wobei n und m der jeweilige Stichprobenumfang sind.
-
Die ANOVA wird verwendet, um die Gleichheit der Mittelwerte in drei oder mehr Gruppen zu testen, die aus normalverteilten Grundgesamtheiten mit gleichen Varianzen stammen. Wir erhalten die F-Verteilung mit (k - 1, n - k) Freiheitsgraden, wobei k die Anzahl der Gruppen und n der gesamte Stichprobenumfang (in allen Gruppen zusammen) ist.
-
Ein Test auf Gesamtsignifikanz der Regressionsanalyse. Die Teststatistik hat eine F-Verteilung mit (k - 1, n - k) Freiheitsgraden, wobei n die Stichprobengröße und k die Anzahl der Variablen (einschließlich des Achsenabschnitts) ist.
Nachdem du mit dem obigen Test das Vorhandensein der linearen Beziehung in deiner Datenstichprobe festgestellt hast, kannst du das Bestimmtheitsmaß R2 berechnen, das die Stärke dieser Beziehung angibt. Du kannst dies hanfschriftlich tun oder unseren Bestimmtheitsmaß Rechner (R-Quadrat) 🇺🇸 verwenden.
-
Ein Test zum Vergleich zweier verschachtelter Regressionsmodelle. Die Teststatistik folgt der F-Verteilung mit (k2 - k1, n - k2) Freiheitsgraden, wobei k1 und k2 die Anzahl der Variablen im kleineren bzw. größeren Modell und n der Stichprobenumfang sind.
Du wirst feststellen, dass der F-Test für die Gesamtsignifikanz eine besondere Form des F-Tests für den Vergleich zweier verschachtelter Modelle ist: Er prüft, ob unser Modell signifikant besser abschneidet als das Modell ohne Prädiktoren (d. h. das reine Achsenabschnitts-Modell).
FAQs
Kann der p-Wert negativ sein?
Nein, der p-Wert kann nicht negativ sein. Das liegt daran, dass Wahrscheinlichkeiten nicht negativ sein können. Der p-Wert ist die Wahrscheinlichkeit, dass die Teststatistik bestimmte Bedingungen erfüllt.
Was bedeutet ein hoher p-Wert?
Ein hoher p-Wert bedeutet, dass für die Nullhypothese eine hohe Wahrscheinlichkeit dafür besteht, dass die Teststatistik bei einer anderen Stichprobe einen Wert erzeugt, der mindestens so extrem ist wie der, der in der dir bereits vorliegenden Stichprobe beobachtet wurde. Ein hoher p-Wert erlaubt es dir nicht, die Nullhypothese zu verwerfen, du solltest sie annehmen.
Was bedeutet ein niedriger p-Wert?
Ein niedriger p-Wert bedeutet, dass für die Nullhypothese die Wahrscheinlichkeit gering ist, dass die Teststatistik bei einer anderen Stichprobe einen Wert erzeugt, der mindestens so extrem ist wie der Wert, der bei der dir bereits vorliegenden Stichprobe beobachtet wurde. Ein niedriger p-Wert spricht für die Alternativhypothese – er ermöglicht es dir, die Nullhypothese zu verwerfen.