Eccoci nel nostro calcolatore per il valore p! Non dovrai più chiederti come trovare il valore p o il p-value, perché qui potrai determinare i valore p unilaterali e bilaterali dei test statistici, seguendo tutte le distribuzioni più diffuse; normale, t di Student, chi-quadrato e F di Snedecor.
I valore p sono presenti in tutti i campi scientifici, ma molti trovano il concetto un po' intimidatorio. Non preoccuparti — in questo articolo ti spiegheremo non solo cos'è il valore p, ma anche come interpretare correttamente i valore p. Ti interessa sapere come calcolare il valore p a mano? Ti forniamo anche tutte le formule necessarie!
🙋 Se vuoi ripassare alcune nozioni di base di statistica, il nostro calcolatore per la distribuzione normale è un ottimo punto di partenza.
Che cos'è il valore p?
Formalmente, il valore p è la probabilità che la statistica del test produca valori almeno altrettanto estremi di quelli che ha prodotto per il tuo campione. È fondamentale ricordare che questa probabilità è è calcolata supponendo che l’ipotesi nulla H0 sia vera!
Più intuitivamente, il valore p risponde alla domanda:
Supponendo di vivere in un mondo in cui l'ipotesi nulla è vera, qual è la probabilità che, per un altro campione, il test che sto eseguendo generi un valore almeno altrettanto estremo di quello che ho osservato per il campione che già possiedo?
È l'ipotesi alternativa che determina il significato di "estremo", quindi il valore p dipende dall'ipotesi alternativa dichiarata; unilaterale sinistra, unilaterale destra o bilaterale. Nelle formule seguenti, S sta per una statistica di prova, x per il valore che ha prodotto per un dato campione e Pr(evento | H0) è la probabilità di un evento, calcolata sotto l'ipotesi che H0 sia vera:
-
Test unilaterale sinistro: valore p = Pr(S ≤ x | H0);
-
Test unilaterale destro: valore p = Pr(S ≥ x | H0); e
-
Test bilaterale:
valore p = 2 × min{Pr(S ≤ x | H0), Pr(S ≥ x | H0)}
(Con min{a,b} indichiamo il numero minore tra a e b)
Se la distribuzione della statistica del test sotto H0 è simmetrica rispetto a 0, allora:
valore p = 2 × Pr(S ≥ |x| | H0)o, equivalentemente:
valore p = 2 × Pr(S ≤ -|x| | H0)
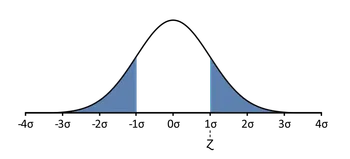
Poiché un'immagine vale più di mille parole, illustriamo queste definizioni. In questo caso, utilizziamo il fatto che la probabilità può essere ordinatamente rappresentata come l'area sotto la curva di densità per una data distribuzione. Forniamo due serie di immagini — una per una distribuzione simmetrica e l'altra per una distribuzione asimmetrica (non simmetrica).
- Caso simmetrico — distribuzione normale:
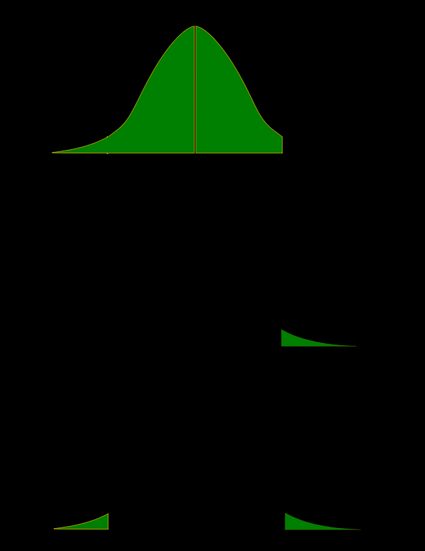
- Caso asimmetrico — distribuzione di chi-quadrato:
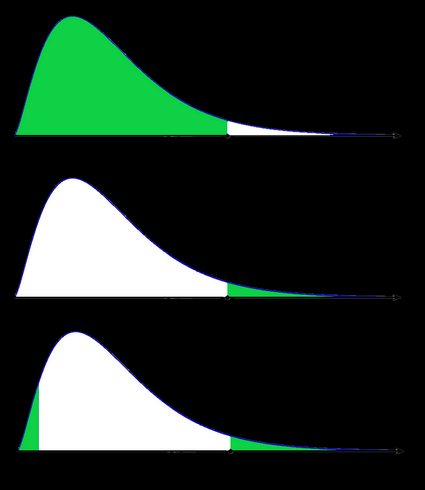
Nell'ultima immagine (il valore p bilaterale per una distribuzione asimmetrica), l'area del lato sinistro è uguale all'area del lato destro.
Come faccio a calcolare il valore p dalla statistica del test?
Per determinare il valore p, devi conoscere la distribuzione della tua statistica di test nell'ipotesi che l'ipotesi nulla sia vera. Quindi, con l'aiuto della funzione di distribuzione cumulativa (cdf) di questa distribuzione, possiamo esprimere la probabilità che la statistica del test sia almeno pari al suo valore x per il campione:
-
Test unilaterale sinistro:
valore p = cdf(x);
-
Test unilaterale destro:
valore p = 1 - cdf(x); e
-
Test bilaterale:
valore p = 2 × min{cdf(x) , 1 - cdf(x)}.
Se la distribuzione della statistica del test sotto H0 è simmetrica rispetto a 0, allora il valore p della distribuzione bilaterale può essere semplificato in valore p = 2 × cdf(-|x|) o, equivalentemente, in valore p = 2 - 2 × cdf(|x|).
Le distribuzioni di probabilità più diffuse nei test di ipotesi tendono ad avere formule cdf complicate e trovare il valore p a mano potrebbe non essere possibile. Probabilmente dovrai ricorrere al computer o a una tabella statistica, dove sono stati raccolti i valori approssimativi della cdf.
Bene, ora sai come calcolare il valore p, ma...come mai devi calcolare questo numero? Nei test di ipotesi, l'approccio del valore p è un'alternativa all'approccio del valore critico. Ricordiamo che quest'ultimo richiede ai ricercatori di impostare in anticipo il livello di significatività, α, che è la probabilità di scartare l'ipotesi nulla quando è vera (quindi di errore di tipo I). Una volta ottenuto il valore p, basta confrontarlo con un dato α per decidere rapidamente se scartare o meno l'ipotesi nulla a quel livello di significatività α. Per maggiori dettagli, consulta la prossima sezione, dove spiegheremo come interpretare i valore p.
Scopri di più su questo argomento nel nostro articolo: "Valore p per l'Ipotesi Nulla: Quando Rifiutare l'Ipotesi Nulla 🇺🇸"*.
Come interpretare il valore p
Come abbiamo detto sopra, il valore p è la risposta alla seguente domanda:
Supponendo di vivere in un mondo in cui l'ipotesi nulla è valida, qual è la probabilità che, per un altro campione, il test che sto eseguendo generi un valore almeno altrettanto estremo di quello osservato per il campione che ho già?
Cosa significa questo per te? Beh, hai due opzioni:
- Un valore p elevato significa che i tuoi dati sono altamente compatibili con l'ipotesi nulla; e
- Un valore p ridotto fornisce prove contro l'ipotesi nulla, in quanto significa che il tuo risultato sarebbe molto improbabile se l'ipotesi nulla fosse vera.
Tuttavia, può accadere che l'ipotesi nulla sia vera, ma che il tuo campione sia estremamente insolito! Ad esempio, immaginiamo di aver studiato l'effetto di un nuovo farmaco e di aver ottenuto un valore p di 0,03. Ciò significa che nel 3% degli studi simili, il caso sarebbe ancora in grado di produrre il valore della statistica del test che abbiamo ottenuto, o un valore ancora più estremo, anche nel caso in cui il farmaco non dovesse avere alcun effetto!
Alla domanda "cos'è il valore p" si può rispondere anche come segue — il valore p ha il minimo livello di significatività nel caso in cui l'ipotesi nulla è stata scartata. Quindi, se vuoi prendere una decisione sull'ipotesi nulla a un certo livello di significatività α, confronta il tuo valore p con α:
- Se il valore p è ≤ α, allora scarta l'ipotesi nulla e accetta l'ipotesi alternativa; o
- Se valore p ≥ α, allora non hai prove sufficienti per scartare l'ipotesi nulla.
Ovviamente, il destino dell'ipotesi nulla dipende da α. Ad esempio, se il valore p fosse 0,03, scarteremmo l'ipotesi nulla a un livello di significatività di 0,05, ma non a un livello di 0,01. Ecco perché il livello di significatività deve essere indicato in anticipo e non adattato opportunamente dopo che il valore p è stato stabilito! Un livello di significatività di 0,05 è il valore più comune, ma non ha nulla di magico. . È sempre meglio riportare il valore p e lasciare che il lettore tragga le proprie conclusioni. Se vuoi saperne di più, leggi il nostro articolo: "Cosa Significa un Valore p di Meno di 0,05? 🇺🇸"*
Inoltre, tieni presente che la competenza nell'area tematica (e la buon senso) è fondamentale. Altrimenti, applicando senza criterio i principi statistici, puoi facilmente arrivare al valore
Come calcolare il valore p a mano?
Se desideri determinare il valore p a mano, segui questi passi:
- Definisci l'ipotesi nulla e le ipotesi alternative;
- Calcola la statistica del test;
- Determina la distribuzione delle statistiche del test;
- Trova il valore p utilizzando una tabella o questo calcolatore del valore p; e
- Confronta il valore p con il livello di significatività.
Come usare il calcolatore per il valore p dalla statistica del test
Con il nostro calcolatore per il valore p non dovrai più chiederti come trovare il valore p di tutti quei complicati test statistici! Ecco i passi da seguire:
-
Scegli l'ipotesi alternativa — bilaterale, unilaterale destr0 o unilaterale sinistro;
-
Indica la distribuzione della tua statistica di test sotto l'ipotesi nulla — è N(0,1), t si Student, chi-quadrato o F di Snedecor? Se non ti convince, consulta le sezioni seguenti, che sono dedicate a queste distribuzioni;
-
Se necessario, specifica i gradi di libertà della distribuzione della statistica del test;
-
Inserisci il valore della statistica del test calcolata per il tuo campione di dati;
-
Per impostazione predefinita, il calcolatore utilizza un livello di significatività di 0,05; e
-
Il nostro calcolatore determina il valore p della statistica del test e fornisce la decisione da prendere sull'ipotesi nulla.
Come posso trovare il valore p dal test Z?
In termini di funzione di distribuzione cumulativa della distribuzione normale standard, tradizionalmente indicata con Φ, il valore p è dato dalle seguenti formule:
-
Test Z a coda sinistra:
valore p = Φ(Zpunteggio);
-
Test Z a coda destra:
valore p = 1 - Φ(Zpunteggio); o
-
Test Z bilaterale (a due code):
valore p = 2 × Φ(-|Zpunteggio|)
oppure
valore p = 2 - 2 × Φ(|Zpunteggio|).
🙋 Per saperne di più sui Z-test o punteggi Z, visita il calcolatore per il Z-test di Omni.
Utilizziamo il punteggio Z o Z-score se la statistica del test segue approssimativamente la distribuzione normale N(0,1). Grazie al teorema del limite centrale, puoi contare su questa approssimazione se disponi di un campione ampio (ad esempio almeno 50 punti dati) e se consideri la distribuzione normale.
Un test Z si riferisce più spesso alla verifica della media della popolazione o alla differenza tra due medie della popolazione, in particolare tra due proporzioni. I test Z si trovano anche nelle stime di massima verosimiglianza.

Valore p dal test Z: Un esempio
Possiamo esplorare il processo di ricerca del valore p dal punteggio Z con un esempio. Supponiamo che un'azienda per i diritti dei consumatori voglia testare l'ipotesi nulla utilizzando confezioni di noci. Ogni confezione di noci contiene esattamente 78 noci e l'azienda può esaminare questa affermazione contro l'ipotesi nulla, che afferma che la confezione non contiene esattamente 78 noci.
Considerando che in un campione di 100 pacchetti, la quantità media di noci è di 76 con una deviazione standard della popolazione di 13,5 e la media della popolazione è 80. Un test bilaterale fornisce prove sufficienti per rifiutare l'ipotesi nulla?
Per trovare la risposta, calcoliamo il punteggio Z considerando i dati seguenti: , , e . Ora, possiamo sostituire questi parametri nella formula per il punteggio Z:
Guardando una tabella del punteggio Z possiamo verificare che Φ(2,96) = 0,0015, quindi, valore p = 2 × 0,0015 = 0,003.
Pertanto, poiché 0,003<0,05, l'ipotesi nulla è statisticamente significativa.
Come posso trovare il valore p da t?
Il valore p del T-score o il punteggio T è dato dalle seguenti formule, in cui cdft,d indica la funzione di distribuzione cumulativa della distribuzione t di Student con d gradi di libertà:
-
Test t unilaterale sinistro:
valore p = cdft,d(tpunteggio);
-
Test t unilaterale destro:
valore p = 1 - cdft,d(tpunteggio); o
-
Test t bilaterale:
valore p = 2 × cdft,d(-|tpunteggio|)
oppure
valore p = 2 - 2 × cdft,d(|tpunteggio|).
Usa l'opzione punteggio T se la statistica del test segue la distribuzione t di Student. Questa distribuzione ha una forma simile a quella di N(0,1) (a campana e simmetrica) ma ha code più pesanti — la forma esatta dipende dal parametro chiamato gradi di libertà. Se il numero di gradi di libertà è elevato (>30), cosa che generalmente accade per i campioni di grandi dimensioni, la distribuzione t di Student è praticamente indistinguibile dalla distribuzione normale N(0,1).

I test t più comuni sono quelli per le medie di una popolazione con una deviazione standard sconosciuta, oppure per la differenza tra le medie di due popolazioni, con deviazioni standard uguali o disuguali, ma sconosciute. Esiste anche un test t per campioni accoppiati (dipendenti).
🙋 Per saperne di più sulle statistiche t, ti consigliamo di utilizzare il nostro calcolatore per il test t.
Il valore p dal punteggio chi-quadrato (punteggio χ²)
Usa l'opzione χ²-score quando esegui un test in cui la statistica del test segue la distribuzione di χ².
Questa distribuzione si verifica se, ad esempio, prendi la somma di variabili al quadrato, ognuna delle quali segue la distribuzione normale N(0,1). Ricordati di controllare il numero di gradi di libertà della distribuzione χ² della tua statistica di prova!

Come trovare il valore p dal punteggio chi-quadrato? Puoi farlo con l'aiuto delle seguenti formule, in cui cdfχ²,d indica la funzione di distribuzione cumulativa della distribuzione χ² con d gradi di libertà:
-
Test del χ² unilaterale sinistro:
valore p = cdfχ²,d(χ²punteggio);
-
Test del χ² unilaterale destro:
valore p = 1 - cdfχ²,d(χ²punteggio)
Ricorda che i test χ² per la bontà dell'adattamento e l'indipendenza sono test unilaterale destro! (vedi sotto); o
-
Test χ² a bilaterale:
valore p = 2 × min{cdfχ²,d(χ²punteggio), 1 - cdfχ²,d(χ²punteggio)}
(Con min{a,b} indichiamo il più piccolo dei numeri a e b).
I test più diffusi che portano a un punteggio di χ² sono i seguenti:
-
Verifica se la varianza dei dati normalmente distribuiti ha un valore predeterminato. In questo caso, la statistica del test ha una distribuzione χ² con n - 1 gradi di libertà, dove n è la dimensione del campione. Può trattarsi di un test unilaterale o bilaterale.
-
Il test di idoneità verifica se la distribuzione empirica (del campione) concorda con una distribuzione di probabilità prevista. In questo caso, la statistica del test segue la distribuzione χ² con k - 1 gradi di libertà, dove k è il numero di classi in cui è suddiviso il campione. Si tratta di un test unilaterale destro.
-
Il test di indipendenza viene utilizzato per determinare se esiste una relazione statisticamente significativa tra due variabili. In questo caso, la statistica del test si basa sulla tabella di contingenza e segue la distribuzione χ² con (r - 1)(c - 1) gradi di libertà, dove r è il numero di righe e c è il numero di colonne della tabella di contingenza. Anche questo è un test unilaterale destro.
Il valore p dal misura F
Infine, l'opzione misura F deve essere utilizzata quando si esegue un test in cui la statistica del test segue la distribuzione F, nota anche come distribuzione di Fisher-Snedecor. La forma esatta di una distribuzione F dipende da due gradi di libertà.

Per capire da dove provengono questi gradi di libertà, considera le variabili casuali indipendenti X e Y, che seguono entrambe la distribuzione χ² con d1 e d2 gradi di libertà, rispettivamente. In questo caso, il rapporto (X/d1)/(Y/d2) segue la distribuzione F, con (d1, d2) gradi di libertà. Per questo motivo, i due parametri d1 e d2 sono chiamati anche gradi di libertà del numeratore e del denominatore.
Il valore p della misura F o il punteggio F è dato dalle seguenti formule, dove lasciamo che cdfF,d1,d2 indichi la funzione di distribuzione cumulativa della distribuzione F, con (d1, d2) gradi di libertà:
-
Test F unilaterale sinistro:
valore p = cdfF,d1,d2(Fpunteggio);
-
Test F unilaterale destro:
valore p = 1 - cdfF,d1,d2(Fpunteggio); o
-
Test F bilaterale:
valore p = 2 × min{cdfF,d1,d2(Fpunteggio), 1 - cdfF,d1,d2(Fpunteggio)}
(Con min{a,b} indichiamo il più piccolo dei numeri a e b).
Di seguito elenchiamo i test più importanti che producono gli misura F. Tutti i test sono unilaterali destri.
-
Un test per la disparità delle varianze in due popolazioni normalmente distribuite. La sua statistica segue la distribuzione F con (n - 1, m - 1) gradi di libertà, dove n e m sono le rispettive dimensioni del campione.
-
L'analisi della varianza, ANOVA, viene utilizzata per testare l'uguaglianza delle medie in tre o più gruppi che provengono da popolazioni normalmente distribuite con varianze uguali. Si ottiene la distribuzione F con (k - 1, n - k) gradi di libertà, dove k è il numero di gruppi e n è la dimensione totale del campione (in tutti i gruppi).
-
Un test per la significatività complessiva dell'analisi di regressione. La statistica del test ha una distribuzione F con (k - 1, n - k) gradi di libertà, dove n è la dimensione del campione e k è il numero di variabili (inclusa l'intercetta).
Una volta stabilita la presenza della relazione lineare nel tuo campione di dati con il test di cui sopra, puoi calcolare il coefficiente di determinazione, R2, che indica la forza di questa relazione. Puoi farlo a mano o utilizzare il nostro calcolatore del coefficiente di determinazione 🇺🇸.
-
Un test per confrontare due modelli di regressione annidati. La statistica del test segue la distribuzione F con (k2 - k1, n - k2) gradi di libertà, dove k1 e k2 sono rispettivamente il numero di variabili nel modello più piccolo e in quello più grande e n è la dimensione del campione.
Potrai notare che il test F di significatività globale è una forma particolare del test F per il confronto di due modelli annidati: verifica se il nostro modello è significativamente migliore del modello senza predittori (cioè il modello lineare).
*Articoli disponibili in inglese
FAQ
Il valore p può essere negativo?
No, il valore p non può essere negativo. Perché le probabilità non possono essere negative e il valore p è la probabilità che la statistica del test soddisfi determinate condizioni.
Cosa significa un valore p elevato?
Un valore p elevato significa che, in base all'ipotesi nulla, c'è un'alta probabilità che per un altro campione la statistica di prova generi un valore almeno altrettanto estremo di quello osservato nel campione già in tuo possesso. Un valore p elevato non consente di scartare l'ipotesi nulla.
Cosa significa un basso valore p?
Un valore p basso significa che, in base all'ipotesi nulla, c'è poca probabilità che per un altro campione la statistica di prova generi un valore almeno altrettanto estremo di quello osservato per il campione di cui si dispone. Un valore p basso è una prova a favore dell'ipotesi alternativa — ti permette di scartare l'ipotesi nulla.