Ce calculateur de test Z vous aide à effectuer un test Z à un échantillon sur la moyenne de la population. Il existe deux formes de ce test (le test Z bilatéral et le test Z unilatéral) qui peuvent être utilisées en fonction de vos objectifs. Vous pouvez également choisir si le calculateur doit déterminer la valeur p du test Z ou si vous préférez utiliser l'approche de la valeur critique !
Poursuivez votre lecture pour en savoir plus sur le test Z en statistique et, en particulier, pour savoir quand utiliser les tests Z, quelle est la formule du test Z et s'il convient d'utiliser le test Z plutôt que le test de Student. En prime, nous vous proposons quelques exemples pour apprendre à effectuer des tests Z pas à pas !
Vous pouvez également consulter notre calculateur de statistiques du test de Student, qui vous permettra d'apprendre le concept d'une autre statistique essentielle. Si vous êtes par ailleurs intéressé·e par le test F, consultez notre calculateur de statistiques du test F 🇺🇸.
Qu'est-ce qu'un test Z ?
Le test Z à un échantillon est l'un des tests de position les plus populaires. L'hypothèse nulle est que la valeur moyenne de la population est égale à un nombre donné, :
Nous effectuons un test Z bilatéral pour tester si la moyenne de la population n'est pas :
Nous effectuons un test Z unilatéral pour tester si la moyenne de la population est inférieure ou supérieure à :
Examinons maintenant les hypothèses d'un test Z à un échantillon.
Quand doit-on utiliser les tests Z ?
Vous pouvez utiliser un test Z si votre échantillon est constitué de points de données indépendants et :
-
les données sont normalement distribuées, et vous connaissez la variance de la population ; ou
-
l'échantillon est grand et les données suivent une distribution dont la moyenne et la variance sont finies. Vous n'avez pas besoin de connaître la variance de la population.
La raison pour laquelle ces deux possibilités existent est que nous voulons que les statistiques de test suivent la loi normale centrée réduite . Dans le premier cas, il s'agit d'une loi normale centrée réduite exacte, tandis que dans le second, elle l'est approximativement, grâce au théorème de la limite centrale.
Une question demeure : quand mon échantillon est-il considéré comme grand ? Il n'y a pas de critère universel. En général, plus vous avez de points de données, mieux l'approximation fonctionne. Les manuels de statistique recommandent de disposer d'au moins 50 points de données, tandis que 30 est considéré comme le strict minimum.
Formule du test Z
Soit un échantillon indépendant suivant la loi normale , c'est-à-dire avec une moyenne égale à , et une variance égale à .
Nous prenons l'hypothèse nulle :
Nous définissons la statistique de test, Z, comme suit :
où :
-
– la moyenne de l'échantillon, soit
-
– la moyenne établie dans
-
– la taille d'échantillon
-
– l'écart type de la population
Dans ce qui suit, majuscule représente la statistique du test (traitée comme une variable aléatoire), tandis que minuscule désigne une valeur réelle de , calculée pour un échantillon donné tiré de N(μ,σ²).
Si est valable, la somme suit la distribution normale, avec une moyenne et une variance . Comme est la normalisation (score Z) de , nous pouvons conclure que la statistique du test suit la loi normale centrée réduite , à condition que soit vrai. D'ailleurs, nous avons le calculateur de score Z si vous voulez vous concentrer sur ce seul score et un article sur le score Z et la value p 🇺🇸 pour mieux comprendre les deux concepts.
Si nos données ne suivent pas une loi normale, ou si l'écart type de la population est inconnu (et donc dans la formule pour nous remplaçons l'écart type de la population par l'écart type de l'échantillon), alors la statistique du test ne suit pas nécessairement une loi normale. Cependant, si l'échantillon est suffisamment grand, le théorème de la limite centrale garantit que suit approximativement .
Dans les sections suivantes, nous vous expliquerons comment utiliser la valeur de la statistique de test, , pour prendre une décision, et s'il faut ou non rejeter l'hypothèse nulle. Deux approches peuvent être utilisées pour parvenir à cette décision : l'approche de la valeur p et l'approche de la valeur critique ; et nous expliquons les deux approches ! Laquelle devriez-vous utiliser ? Dans le passé, l'approche de la valeur critique était plus populaire parce qu'il était difficile de calculer la valeur p à partir d'un test Z. Cependant, grâce aux ordinateurs modernes, nous pouvons le faire assez facilement, et avec une bonne précision. En général, il est fortement conseillé de donner la valeur p de vos tests !
Valeur p du test Z
Formellement, la valeur p est le plus petit seuil de signification auquel l'hypothèse nulle peut être rejetée. Plus intuitivement, la valeur p répond aux questions suivantes.
À condition que l'on vive dans un monde où l'hypothèse nulle se vérifie, quelle est la probabilité que la valeur de la statistique du test soit au moins aussi extrême que la valeur que l'on a obtenue pour notre échantillon ? Par conséquent, une petite valeur p signifie que votre résultat est très improbable sous l'hypothèse nulle, et qu'il y a donc une forte probabilité que l'hypothèse nulle soit rejetée (plus la valeur p est petite, plus la probabilité que l'hypothèse soit rejetée est forte).
Pour trouver la valeur p, vous devez calculer la probabilité que la statistique du test, , soit au moins aussi extrême que la valeur observée, , si l'hypothèse nulle est vraie (la probabilité d'un événement calculée en supposant que est vraie sera notée .) C'est l'hypothèse alternative qui détermine ce que signifie plus extrême :
- Test Z bilatéral : les valeurs extrêmes sont celles dont la valeur absolue dépasse , c'est-à-dire celles qui sont inférieures à ou supérieures à . Par conséquent, nous avons :
La symétrie de la loi normale donne :
- Test Z unilatéral à gauche : les valeurs extrêmes sont celles qui sont inférieures à , ce qui nous donne :
- Test Z unilatéral à droite : les valeurs extrêmes sont celles qui sont supérieures à , nous avons donc :
Pour calculer ces probabilités, nous pouvons utiliser la fonction de répartition (angl. cumulative distribution function, cdf) de , qui, pour un nombre réel, , est définie comme suit :
En outre, les valeurs p peuvent être représentées comme l'aire sous la fonction de densité (angl. probability density function, pdf) de , en raison de :
Test Z bilatéral et test Z unilatéral
Avec tout ce que vous avez appris dans la section précédente, vous êtes prêt·e à vous familiariser avec les tests Z.
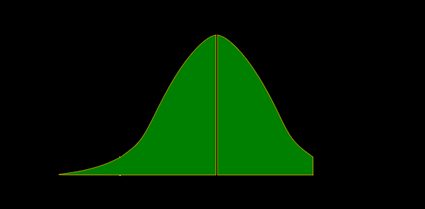
- Test Z bilatéral :
Du fait que , on en déduit que :
La valeur p est l'aire sous la fonction de densité (pdf) à la fois à gauche de , et à droite de :
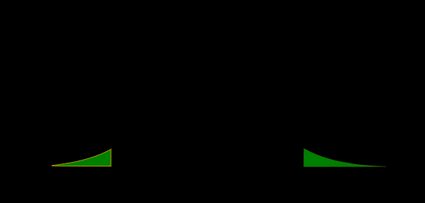
- Test Z unilatéral à gauche :
La valeur p est l'aire sous la courbe de la fonction de densité à gauche de notre :
- Test Z unilatéral à droite :
La valeur p est l'aire sous la courbe de la fonction de densité à droite de :

La décision de rejeter ou non l'hypothèse nulle peut maintenant être prise à n'importe quel seuil de signification, , que vous souhaitez !
-
Si la valeur p est inférieure ou égale à , l'hypothèse nulle est rejetée à ce seuil de signification.
-
Si la valeur p est supérieure à , il n'y a pas suffisamment de preuves pour rejeter l'hypothèse nulle à ce seuil de signification.
Valeurs critiques et régions critiques du test Z
L'approche des valeurs critiques consiste à comparer la valeur de la statistique de test obtenue pour notre échantillon, , aux valeurs dites critiques. Ces valeurs constituent les limites des régions où il est très improbable que la statistique du test se trouve. Ces régions sont souvent appelées régions critiques ou régions de rejet. La décision de rejeter ou non l'hypothèse nulle repose alors sur l'appartenance ou non de notre à la région critique.
Les régions critiques dépendent du seuil de signification, , du test et de l'hypothèse alternative. Le choix de est arbitraire ; dans la pratique, les valeurs de 0,1, 0,05 ou 0,01 sont le plus souvent utilisées pour .
Une fois que nous nous sommes mis d'accord sur la valeur de , nous pouvons facilement déterminer les régions critiques du test Z :
- Test Z bilatéral :
- Test Z unilatéral à gauche :
- Test Z unilatéral à droite :
Pour décider du sort de , vérifiez si votre se trouve ou non dans la région critique.
-
Si oui, rejetez et acceptez .
-
Si non, il n'y a pas suffisamment de preuves pour rejeter .
Comme vous le voyez, les formules pour les valeurs critiques des tests Z impliquent l'inverse, , de la fonction de répartition (cdf) de .
Exemples du test Z
Pour s'assurer que vous avez bien compris l'essence du test Z, passons en revue quelques exemples :
-
Une machine pour remplir des bouteilles suit une loi normale. Son écart type, tel que déclaré par le fabricant, est égal à 30 mL. Un vendeur de jus de fruits affirme que le volume versé dans chaque bouteille est, en moyenne, d'un litre, soit 1 000 mL, mais nous soupçonnons qu'en fait le volume moyen est plus petit que cela…
Formellement, les hypothèses que nous posons sont les suivantes :
Nous sommes allés dans un magasin et avons acheté un échantillon de 9 bouteilles. Après avoir mesuré prudemment le volume de jus de chaque bouteille, nous avons obtenu l'échantillon suivant (en millilitres).
-
Taille de l'échantillon : .
-
Moyenne de l'échantillon : .
-
Écart type de la population : .
-
Ainsi, nous obtenons :
-
-
Par conséquent, .
Comme , nous concluons que nos soupçons ne sont pas infondés ; au seuil de signification le plus courant, 0,05, nous rejetterions l'affirmation du producteur, , et accepterions l'hypothèse alternative, .
-
Nous avons lancé une pièce de monnaie 50 fois. Nous avons obtenu 20 fois pile et 30 fois face. Les preuves sont-elles suffisantes pour affirmer que la pièce est pipée ?
Il est clair que nos données suivent une loi de Bernoulli, avec une probabilité de succès et une variance . Cependant, l'échantillon étant grand, nous pouvons effectuer un test Z en toute sécurité. Nous adoptons la convention selon laquelle le fait d'obtenir pile est un succès.
Énonçons l'hypothèse nulle et l'hypothèse alternative.
-
(la pièce est équilibrée: la probabilité d'obtenir pile est de ).
-
(la pièce est pipée : la probabilité d'obtenir pile diffère de ).
Dans notre échantillon, nous avons 20 succès (notés par des 1) et 30 échecs (notés par des 0).
-
Taille de l'échantillon .
-
Moyenne de l'échantillon .
-
L'écart type de la population est donné par (car est la proportion supposée dans ). Par conséquent, .
-
- Nous avons :
- Et, nous obtenons :
Parce que nous n'avons pas assez de preuves pour rejeter l'affirmation selon laquelle la pièce est juste, même à un seuil de signification aussi élevé que . Dans ce cas, vous pouvez lancer votre pièce sans crainte ou utiliser le calculateur de pile ou face pour connaître vos chances d'obtenir, par exemple, 10 face d'affilée (ces chances sont extrêmement faibles !).
FAQ
Quelle est la différence entre le test Z et le test de Student ?
Nous utilisons le test de Student pour tester la moyenne de la population d'un ensemble de données normalement distribuées dont l'écart type de la population est inconnu. Nous obtenons cela en remplaçant l'écart type de la population dans la formule de la statistique du test Z par l'écart type de l'échantillon. Cela signifie que cette nouvelle statistique de test suit (à condition que H₀ soit valable) la loi de Student à n-1 degrés de liberté au lieu de N(0,1).
Quand doit-on utiliser le test de Student plutôt que le test Z ?
Pour les grands échantillons, la loi de Student avec n degrés de liberté se rapproche de la loi N(0,1). Par conséquent, tant qu'il y a un nombre suffisant de points de données (au moins 30), il importe peu que vous utilisiez le test Z ou le test de Student, puisque les résultats seront presque identiques. Toutefois, pour les petits échantillons dont la variance est inconnue, pensez à utiliser le test de Student à la place du test Z.
Comment calculer la statistique du test Z ?
Pour calculer la statistique du test Z :
- Calculez la moyenne arithmétique de votre échantillon.
- Soustrayez de cette moyenne la moyenne établie dans l'hypothèse nulle.
- Multipliez par la racine carrée de la taille de l'échantillon.
- Divisez par l'écart type de la population.
- Voilà, vous venez de calculer la statistique du test Z !
Comment utiliser le calculateur du test Z à un échantillon ?
Notre calculateur vous simplifie la vie !
Choisissez l'hypothèse alternative : bilatérale ou unilatérale à gauche/à droite.
Dans notre calculateur de test Z, vous pouvez décider d'utiliser la valeur p ou l'approche des régions critiques. Dans ce dernier cas, définissez le seuil de signification, α.
Saisissez la valeur de la statistique de test, z. Si vous ne la connaissez pas, vous pouvez entrer certaines données qui nous permettront de calculer votre z.
Les résultats apparaissent immédiatement au bas du calculateur.
Si vous souhaitez trouver z sur la base de la valeur p, n'oubliez pas que dans le cas de tests bilatéraux, il existe deux valeurs possibles de z : une positive et une négative, et qu'il s'agit de nombres opposés. Dans ce cas, le calculateur de test Z renvoie la valeur positive. Pour trouver l'autre valeur possible de z pour une valeur p donnée, il suffit de prendre le nombre opposé à la valeur de z affichée par le calculateur.